鉴于 CPU 的字大小允许它寻址内存中的每个字节。
并通过 PAE 给出这一点CPU 甚至可以使用比字大小更多的位来进行寻址。
CPU 无法一步读取未对齐字的原因是什么?
例如,在 32 位机器中,您可以读取从位置 0 开始的 4 字节 block ,但无法读取从位置 1 开始的 block (可以,但需要几个步骤)。
为什么CPU不能这样做?
最佳答案
问题不在于 CPU 寻址内存中任何单个字节的能力。但它是内存,其粒度不一样。 正如 Oli 所说,这是非常特定于体系结构的,但内存芯片通常通过其数据总线宽度来寻址。这意味着给定的地址代表其数据总线的完整“字”。
让我们以 32 位 CPU 为例,它具有连接到存储设备的 32 位宽数据总线。当CPU想要访问地址0x00000000处的字时,它实际上想要访问字节0,1,2 和 3。然而,对于存储芯片来说,这由单个地址 0x00000000 表示。
现在,当CPU想要访问地址0x00000001处的字时,它实际上想要访问字节1、2, 3 和 4。然而,对于存储芯片,这由地址 0x00000000 处的一段字和地址 0x00000001 处的一段字表示。
因此需要两个总线周期。
编辑:添加一些接线图
为了说明这一点,以下是两种相反的寻址方案:
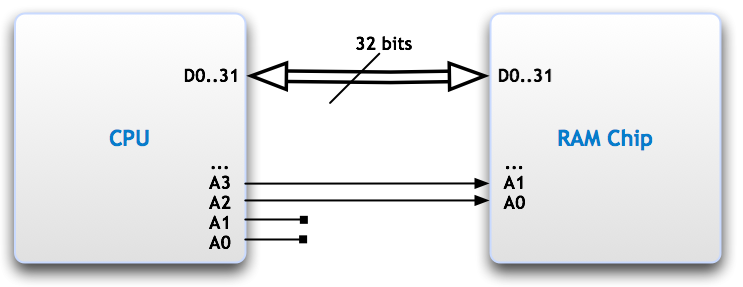
注意 RAM 芯片地址中的位移。
地址将如下所示:
// From the RAM point of view
@0x00000000: Bytes 0x00000000 to 0x00000003
@0x00000001: Bytes 0x00000004 to 0x00000007
要访问双字@0x00000001,您可以看到无法直接寻址。您需要向 RAM 芯片询问地址 0x00000000 和 0x00000001 处的双字。
关于hardware - 为什么无法一步读取未对齐的单词?,我们在Stack Overflow上找到一个类似的问题: https://stackoverflow.com/questions/24228252/