请帮我理解LL Parser中第二个L的最左推导的含义。
用一个最简单的例子来解释一下。
我看到下图解释了最左推导,但我不明白:
最佳答案
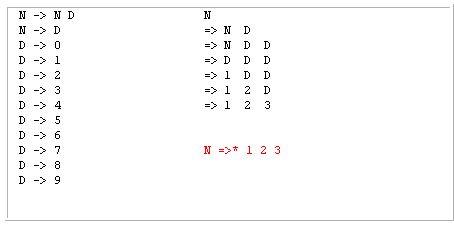
语法规则显示在左侧,包括非终结符和终结符。非终结符应该是大写字母,其他所有符号通常都是终结符。在示例中,N 和 D 是非终结符,0-9 是终结符。最左推导总是使最左非终结符经过语法规则。尝试格式化下面的示例。
N
=> N D --Replaces the first/left most/only (which is "N") with the N => N D rule
=> N D D --Replaces the first/left most nonterminal (which is "N") with the N => N D rule
=> D D D --Replaces the first nonterminal (which is "N") with the N => D rule
=> 1 D D --Replaces the first nonterminal ("D") with the D => 1 rule(our first terminal character!)
=> 1 2 D --Replaces the first nonterminal ("D") with the D => 2 rule
=> 1 2 3 --Replaces the first nonterminal ("D") with the D => 3 rule
-- Only terminal characters remain, derivation/reduction is complete.
关于parsing - 最左推导是什么意思?,我们在Stack Overflow上找到一个类似的问题: https://stackoverflow.com/questions/15194103/