大家好
我正在尝试构建一个用于解析特定于域的语言的词法分析器。 我有一组保留 token (RESERVED 片段)和一个转义字符。每当出现未转义的保留标记时,词法分析器就应进行拆分。
一个简化的示例:
SEP: ';';
AND: '&&';
fragment ESCAPE: '/';
fragment RESERVED: SEP | AND | ESCAPE;
SINGLETOKEN : (~(RESERVED) | (ESCAPE RESERVED))+;
问题:
只要 RESERVED 仅包含单个字符标记,这就可以正常工作。 求反运算 ~ 仅适用于单个字符。
不幸的是,我也需要它与字符串标记一起使用。 因此标记包含超过 1 个字符(请参阅示例中的 AND)。有没有一种简单的方法可以做到这一点? 我需要在不内联 java 或 c 代码的情况下解决问题,因为这必须编译为不同的语言,并且我不想维护单独的副本。
希望有人能帮助我
<小时/>整个脚本的示例输入
创建;假;假;1.key = bla; trig;true;false;(1.key1 ~ .*thisIsRegex || 2.oldKey1 €) && (1.bla=2.blub || 1.blub=bla);
在词法分析器之后,它应该看起来像这样 |标记分隔符空格并不重要:|create|;|false|;|false|;|1.|key| =|bla|;| trig|;|true|;|false|;|(|1.|key1| ~| .*thisIsRegex| || |2.|oldKey1| €|)| && |(|1.|bla|=|2.|blub| || |1.|blub|=|bla|)|;|
整个脚本可以在 http://pastebin.com/Cz520VW4 上找到 (请注意,此链接将在一个月后过期)目前还不适用于正则表达式部分。
<小时/>可能但可怕的解决方案
我找到了一个可能的解决方案,但它确实很糟糕,并且使脚本更容易出错。所以我更愿意找到更干净的东西。
我目前正在做的是手写否定(~保留)。
SEP: ';';
AND: '&&';
fragment ESCAPE: '/';
fragment RESERVED: SEP | AND | ESCAPE;
NOT_RESERVED:
: '&' ~('&' | SEP | ESCAPE)
// any two chars starting with '&' followed by a character other then a reserve character
| ~('&' | SEP | ESCAPE) ~(SEP | ESCAPE)
// other than reserved character followed by '&' followed by any char
;
SINGELTON : (NOT_RESERVED | (ESCAPE RESERVED))+;
真实的脚本有超过 5 个多字符标记,以后可能会有更多超过 2 个字符,所以这种解决问题的方法会变得相当复杂。
最佳答案
It currently does not work for the regex part yet ...
那是因为您已将正则表达式文字声明为任何内容。如果正则表达式文字以保留标记开头,如下所示:1.key1 ~ falser 会怎样?
简而言之,我不建议您按照现在尝试的方式实现词法分析器。相反,就像几乎所有编程语言都实现正则表达式文字一样:让它们由分隔符(或带引号的字符串)封装:
1.key1 ~ /falser/
或者:
1.key1 ~ "falser"
您可以在词法分析器中添加一个标志,每当遇到 ~ 时就会翻转该标志,并根据该标志创建一个正则表达式文字。下面是一个关于如何执行此操作的小演示:
grammar TriggerDescription;
options {
output=AST;
}
tokens {
// seperator
SEP = ';';
// md identifier
OLDMD = '1.';
NEWMD = '2.';
// boolean
TRUE = 'true';
FALSE = 'false';
//atoms
EX = '€';
EQ = '=';
SMEQ = '<=';
GREQ = '>=';
GR = '>';
SM = '<';
// literals
AND = '&&';
OR = '||';
NOT = '!';
OPENP = '(';
CLOSEP = ')';
// token identifier
TRIGGER = 'TRIGGER';
REPFLAG = 'REPFLAG';
LOCALFLAG = 'LOCALFLAG';
TRIGGERID = 'TRIGGERID';
EVALUATOR = 'EVALUATOR';
ROOT = 'ROOT';
}
@lexer::members {
private boolean regexExpected = false;
}
parse
: trigger+ EOF -> ^(ROOT trigger+)
//(t=. {System.out.printf("\%-15s '\%s'\n", tokenNames[$t.type], $t.text);})* EOF
;
trigger
: triggerid SEP repflag SEP exeflag SEP mdEval SEP -> ^(TRIGGER triggerid repflag exeflag mdEval)
;
triggerid
: rs = WORD -> ^(TRIGGERID[$rs])
;
repflag
: rs = TRUE -> ^(REPFLAG[$rs])
| rs = FALSE -> ^(REPFLAG[$rs])
;
exeflag
: rs = TRUE -> ^(LOCALFLAG[$rs])
| rs = FALSE -> ^(LOCALFLAG[$rs])
;
mdEval
: orExp -> ^(EVALUATOR orExp)
;
orExp
: andExp (OR^ andExp)* // Make `||` root
;
andExp
: notExp (AND^ notExp)* // Make `##` root
;
notExp
: (NOT^)*atom // Make `!` root
;
atom
: key EX^
| key MT^ REGEX
| key EQ^ (key | WORD)
| key GREQ^ (key | WORD)
| key SMEQ^ (key | WORD)
| key GR^ (key | WORD)
| key SM^ (key | WORD)
| OPENP orExp CLOSEP -> orExp // removing the parenthesis
;
key : OLDMD rs = WORD -> ^(OLDMD[$rs])
| NEWMD rs = WORD -> ^(NEWMD[$rs])
;
/*------------------------------------------------------------------
* LEXER RULES
*------------------------------------------------------------------*/
// chars used for words might need to be extended
fragment CHAR
: 'a'..'z' | 'A'..'Z' | '0'..'9'
;
// chars used in regex
fragment REG_CHAR
: '|' | '[' | '\\' | '^' | '$' | '.' | '?' | '*' | '+' | '(' | ')'
;
fragment RESERVED
: SEP | ESCAPE | EQ
;
// white spaces taps etc
fragment WS
: '\t' | ' ' | '\r' | '\n'| '\u000C'
;
fragment ESCAPE
: '/'
;
MT
: '~' {regexExpected = true;}
;
REGEX
@after{regexExpected = false;}
: {regexExpected}?=> WS* ~WS+
;
LINE_COMMENT
: '//' ~('\n'|'\r')* '\r'? '\n' {$channel=HIDDEN;}
;
WHITESPACE
: WS+ { $channel = HIDDEN; }
;
COMMENT
: '/*' .* '*/' {$channel=HIDDEN;}
;
WORD : CHAR+
;
这将为您发布的示例输入创建以下 AST:
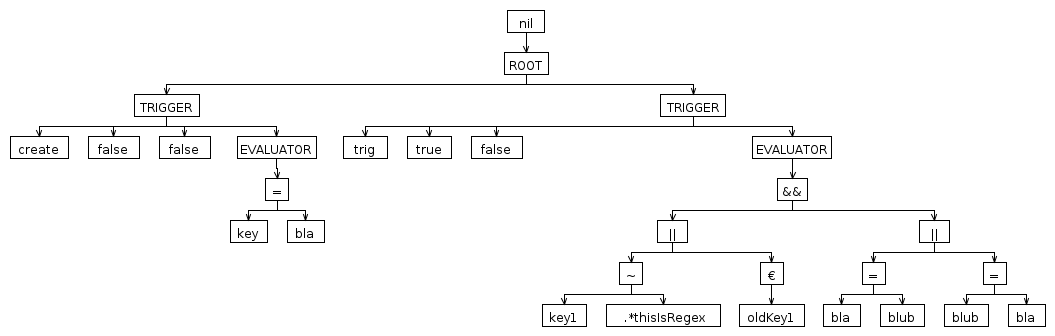
但是,请意识到这只是一个快速演示。我现在定义 REGEX 的方式是它将消耗它看到的任何非空格字符。换句话说,要结束 REGEX,您必须在其后面直接放置一个空格。调整我的示例以满足您自己的需要。
祝你好运!
PS。顺便说一句,REGEX 规则中的奇怪 { ... }?=> 语法称为“门控语义谓词”。在这里了解更多信息:What is a 'semantic predicate' in ANTLR?
关于escaping - ANTLR 词法分析器排除字符串,我们在Stack Overflow上找到一个类似的问题: https://stackoverflow.com/questions/11952369/