请帮助我。我正在使用 Tensorflow 2.0 GPU。 我训练模型并保存为 .h5 格式
model = keras.Sequential()
model.add(layers.Bidirectional(layers.CuDNNLSTM(self._window_size, return_sequences=True),
input_shape=(self._window_size, x_train.shape[-1])))
model.add(layers.Dropout(rate=self._dropout, seed=self._seed))
model.add(layers.Bidirectional(layers.CuDNNLSTM((self._window_size * 2), return_sequences=True)))
model.add(layers.Dropout(rate=self._dropout, seed=self._seed))
model.add(layers.Bidirectional(layers.CuDNNLSTM(self._window_size, return_sequences=False)))
model.add(layers.Dense(units=1))
model.add(layers.Activation('linear'))
model.summary()
model.compile(
loss='mean_squared_error',
optimizer='adam'
)
# обучаем модель
history = model.fit(
x_train,
y_train,
epochs=self._epochs,
batch_size=self._batch_size,
shuffle=False,
validation_split=0.1
)
model.save('rts.h5')
然后我加载这个模型并将其用于预测,一切正常。
model = keras.models.load_model('rts.h5')
y_hat = model.predict(x_test)
但是在 Tensorflow Serving 中使用经过训练的模型时出现了问题。并且不接受.h5格式的模型。 我跑:
sudo docker run --gpus 1 -p 8501:8501 --mount type=bind,source=/home/alex/PycharmProjects/TensorflowServingTestData/RtsModel,target=/models/rts_model -e MODEL_NAME=rts_model -t tensorflow/serving:latest-gpu
但是在 Tensorflow Serving 中使用经过训练的模型时出现了问题。并且不接受.h5格式的模型。 我跑: 我收到错误:
tensorflow_serving/sources/storage_path/file_system_storage_path_source.cc:267] No versions of servable rts_model found under base path /models/rts_model
我尝试按照此处所述保存经过训练的模型,https://www.tensorflow.org/guide/saved_model#using_savedmodel_with_estimators :
我收到错误:
ValueError: Layer has 2 states but was passed 0 initial states.
我尝试按如下方式保存模型,https://www.tensorflow.org/api_docs/python/tf/keras/models/save_model :
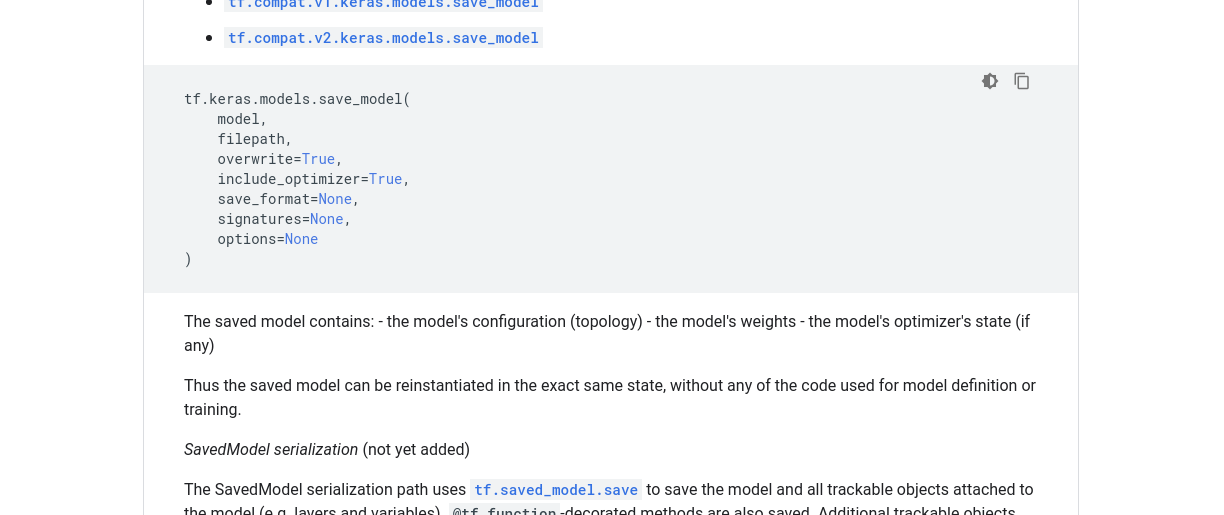
并且有同样的错误:
ValueError: Layer has 2 states but was passed 0 initial states.
唯一可以将模型保存为 Tensorflow Serving 格式的方法是:
keras.experimental.export_saved_model(model, 'saved_model/1/')
在服务中保存模型工作。但我收到一条警告,指出此方法已被弃用,并将在未来版本中删除。
Instructions for updating:
Please use `model.save(..., save_format="tf")` or `tf.keras.models.save_model(..., save_format="tf")`.
它关闭了我。 当我尝试使用这些方法时,出现错误。 当我使用有效的方法时,写道它已被弃用。
请帮忙。 如何在 Tensorflow 2.0 中保存经过训练的模型。以便它可以用于 Tensorflow Serving。
最佳答案
我也正在尝试解决这个问题!
根据答案here普通的 LSTM(即 tf.keras.layers.LSTM)将使用 GPU,并且通常应该在 cuDNNLSTM 类上使用,除非您特别需要原始实现(不确定为什么会这样做)。
根据docs如果满足一些要求,普通的 LSTM 将使用 cuDNN 实现(见下文)。
使用此 LSTM 层时,我可以成功保存到 tf 输出类型,只需使用 model.save_model('output_path', save_format='tf')
使用 cuDNN 的 LSTM 的要求如下(请注意,所有要求均满足默认值):
If a GPU is available and all the arguments to the layer meet the requirement of the CuDNN kernel (see below for details), the layer will use a fast cuDNN implementation.
The requirements to use the cuDNN implementation are:
activation == tanhrecurrent_activation == sigmoidrecurrent_dropout == 0- unroll is False
- use_bias is True Inputs are not masked or strictly right padded.
关于python - Tensorflow 2.0 保存训练好的模型以供服务,我们在Stack Overflow上找到一个类似的问题: https://stackoverflow.com/questions/58649383/