我的程序中有一个 FindFile 例程,它将列出文件,但如果填写了“包含文本”字段,那么它应该只列出包含该文本的文件。
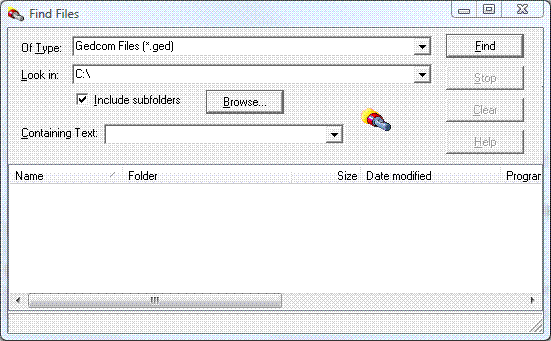
如果输入“包含文本”字段,则我将搜索找到的每个文件以查找该文本。我目前的方法是:
var
FileContents: TStringlist;
begin
FileContents.LoadFromFile(Filepath);
if Pos(TextToFind, FileContents.Text) = 0 then
Found := false
else
Found := true;
上面的代码很简单,一般情况下是可以运行的。但它有两个问题:
对于非常大的文件(例如 300 MB),它会失败
我觉得还可以更快。这还不错,但如果有一种简单的方法可以加快速度,为什么还要花 10 分钟搜索 1000 个文件呢?
我需要它在 Delphi 2009 上工作并搜索可能是或不是 Unicode 的文本文件。它只需要适用于文本文件。
那么如何才能加快搜索速度并使其适用于非常大的文件?
<小时/>奖励:我还想允许“忽略大小写”选项。这是一个更难提高效率的方法。有什么想法吗?
<小时/>解决方案:
嗯,mghie 指出了我之前的问题 How Can I Efficiently Read The First Few Lines of Many Files in Delphi ,正如我所回答的,它是不同的并且没有提供解决方案。
但他让我想到我以前做过这件事,而且我确实这么做了。我为大文件构建了一个 block 读取例程,将其分成 32 MB 的 block 。我用它来读取程序的输入文件,该文件可能很大。这个例程运行良好且快速。因此,第一步是对我正在查看的这些文件执行相同的操作。
所以现在的问题是如何在这些 block 内有效地搜索。好吧,我之前确实有过关于该主题的问题:Is There An Efficient Whole Word Search Function in Delphi? RRUZ 向我指出了 SearchBuf 例程。
这也解决了“奖励”问题,因为 SearchBuf 的选项包括全字搜索(该问题的答案)和 MatchCase/noMatchCase(奖励的答案)。
所以我就出发了。再次感谢 SO 社区。
最佳答案
这里最好的方法可能是使用内存映射文件。
首先你需要一个文件句柄,使用CreateFile windows API 函数。
然后将其传递给 CreateFileMapping获取文件映射句柄。最后使用MapViewOfFile将文件映射到内存中。
要处理大文件,MapViewOfFile能够仅将特定范围映射到内存中,因此您可以例如映射前 32MB,然后使用 UnmapViewOfFile取消映射它,然后是 MapViewOfFile接下来的 32MB 等等。 (编辑:正如下面所指出的,确保您以这种方式映射的 block 重叠 4kb 的倍数,并且至少与您正在搜索的文本的长度一样多,这样您就不会忽略任何文本可能会在 block 边界处 split )
要在文件(部分)映射到内存后进行实际搜索,您可以为 StrPosLen 制作源代码的副本来自 SysUtils.pas(不幸的是,它仅在实现部分中定义,并未在接口(interface)中公开)。保留一份副本不变并制作另一份副本,替换 Wide与 Ansi每次。另外,如果您希望能够在可能包含嵌入的 #0 的二进制文件中进行搜索的,您可以删除 (Str1[I] <> #0) and部分。
找到一种方法来识别文件是 ANSI 还是 Unicode,或者简单地在文件的每个映射部分上调用 Ansi 和 Unicode 版本。
完成每个文件后,请务必调用 CloseHandle首先是文件映射句柄,然后是文件处理。 (并且不要忘记先调用UnmapViewOfFile)。
编辑:
使用内存映射文件而不是使用例如TFileStream 将文件以 block 的形式读入内存的原因是字节只会在内存中出现一次。
通常,在文件访问时,Windows 首先将字节读取到操作系统文件缓存中。然后将它们从那里复制到应用程序内存中。
如果使用内存映射文件,操作系统可以直接将操作系统文件缓存中的物理页映射到应用程序的地址空间,而无需再次复制(减少复制所需的时间并减少一半的内存使用量)。
额外答案:通过调用 StrLIComp 而不是 StrLComp,您可以进行不区分大小写的搜索。
关于delphi - 用Delphi快速搜索大文件中是否存在字符串,我们在Stack Overflow上找到一个类似的问题: https://stackoverflow.com/questions/5012664/