我需要在 JavaScript 中使用正则表达式的帮助。我有以下字符串(没有换行符):
var str = 'DetailedLog 18.11.2015 14:41:35.299 Neutral : 0,5704 Happy : 0,6698 Sad : 0,0013 Angry : 0,0040 Surprised : 0,0129 Scared : 0,0007 Disgusted : 0,0048 Valence : 0,6650 Arousal : 0,2297 Gender : Male Age : 20 - 30 Beard : None Moustache : None Glasses : Yes Ethnicity : Caucasian Y - Head Orientation : -1,7628 X - Head Orientation : 2,5652 Z - Head Orientation : -3,0980 Landmarks : 375,4739 - 121,6879 - 383,2627 - 113,6502 - 390,8202 - 110,3507 - 396,1021 - 109,7039 - 404,9615 - 110,9594 - 443,2603 - 108,9765 - 451,9454 - 106,7192 - 457,1207 - 106,8835 - 464,1162 - 109,5496 - 470,9659 - 116,8992 - 387,4940 - 132,0171 - 406,4031 - 130,4482 - 441,6239 - 128,6356 - 460,6862 - 128,1997 - 419,0713 - 161,6479 - 425,3519 - 155,1223 - 431,9862 - 160,6411 - 406,9320 - 190,3831 - 411,4790 - 188,7656 - 423,1751 - 185,6583 - 428,5339 - 185,6882 - 433,7802 - 184,8167 - 445,6192 - 186,3515 - 450,8424 - 187,2787 - 406,0796 - 191,1880 - 411,9287 - 193,5352 - 417,9666 - 193,6567 - 424,0851 - 193,4941 - 428,6678 - 193,5652 - 433,2172 - 192,7540 - 439,3548 - 192,0136 - 445,4181 - 191,1532 - 451,6007 - 187,9486 - 404,5193 - 190,6352 - 412,8277 - 185,4609 - 421,1355 - 181,2883 - 428,3182 - 181,1826 - 435,2024 - 180,2258 - 443,9292 - 183,2533 - 453,1117 - 187,2288 - 405,9689 - 193,2750 - 410,0249 - 199,8118 - 416,0457 - 203,0374 - 423,4839 - 204,1818 - 429,9247 - 204,2175 - 436,3620 - 203,1305 - 443,4268 - 200,9355 - 448,9572 - 197,1335 - 452,0746 - 190,0314 Quality : 0,8137 Mouth : Closed Left Eye : Open Right Eye : Open Left Eyebrow : Lowered Right Eyebrow : Lowered Identity : NO IDENTIFICATION';
我的目标是从这个困惑中构造一个可用的 JavaScript 对象,其中包含属性及其值。我正在尝试使用正则表达式,因为据我所知,它们的执行速度比使用 custum for 循环进行解析更快。执行此操作的代码需要很快。
对于属性名称,我尝试使用以下代码构造一个字符串数组:
str.match(/(\b[A-Z].*?\b)(?=(\s(:|\d)))/g);
输出:
["DetailedLog", "Neutral", "Happy", "Sad", "Angry", "Surprised", "Scared",
"Disgusted", "Valence", "Arousal", "Gender", "Male Age", "Beard", "None Moustache",
"None Glasses", "Yes Ethnicity", "Caucasian Y - Head Orientation", "X - Head Orientation",
"Z - Head Orientation", "Landmarks", "Quality", "Mouth", "Closed Left Eye",
"Open Right Eye", "Open Left Eyebrow", "Lowered Right Eyebrow", "Lowered Identity"]
这里我遇到了由两个大写单词组成的字符串的问题,例如“Male Age”或“Open Left Eyebrow”或“Closed Left Eye”。我将使用第一个词来表示属性值,因此它会妨碍...
我的第一个问题是给我这个输出的正确正则表达式是什么:
["DetailedLog", "Neutral", "Happy", "Sad", "Angry", "Surprised", "Scared",
"Disgusted", "Valence", "Arousal", "Gender", "Age", "Beard", "Moustache",
"Glasses", "Ethnicity", "Y - Head Orientation", "X - Head Orientation",
"Z - Head Orientation", "Landmarks", "Quality", "Mouth", "Left Eye",
"Right Eye", "Left Eyebrow", "Right Eyebrow", "Identity"]
感谢您的帮助。
最佳答案
正则表达式
(?:(DetailedLog) ([^ ]+ [^ ]+)|(\b[A-Z][A-Za-z -]+?) : ((?:(?:-?[\d,]+)(?: - -?[\d,]+)*|(?:(?:[A-Z ]+\b|[A-Za-z]+)))))(?:$| )
https://regex101.com/r/lP9pG2/3
可视化
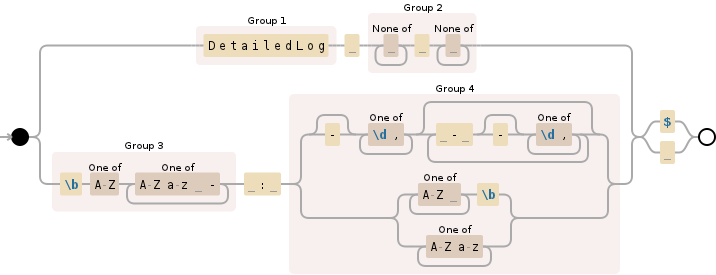
假设
这里的基本思想是,因为我们不知道“键”从哪里开始,所以我们尝试更精确地定义“值”,并在知道值结束时停止捕获。
DetailedLog后面始终会跟有 2 组以空格分隔的字符,这些字符(包括空格)将被视为值。- 在“键”之后,例如
Happy值将是以下之一:- 一个或多个正数或负数,以
-分隔。 - 一个大写字母,后跟一个或多个大写或小写字母。
- 全部大写字符和空格的序列。
- 一个或多个正数或负数,以
请注意,最后一个“所有大写字符和空格的序列”是捕获最后一部分Identity,特别是NO IDENTIFICATION。 Identity 的值或可能仅包含字母和空格的任何其他值如果不全部为大写,则可能会导致问题。
示例代码
var result = {};
var myregexp = /(?:(DetailedLog) ([^ ]+ [^ ]+)|(\b[A-Z][A-Za-z -]+?) : ((?:(?:-?[\d,]+)(?: - -?[\d,]+)*|(?:(?:[A-Z ]+\b|[A-Za-z]+)))))(?:$| )/g;
var match = myregexp.exec(str);
while (match != null) {
if (match[1]) {
result[match[1]] = match[2];
} else {
result[match[3]] = match[4];
}
match = myregexp.exec(str);
}
这会导致结果包含以下对象:
{
"DetailedLog": "18.11.2015 14:41:35.299",
"Neutral": "0,5704",
"Happy": "0,6698",
"Sad": "0,0013",
"Angry": "0,0040",
"Surprised": "0,0129",
"Scared": "0,0007",
"Disgusted": "0,0048",
"Valence": "0,6650",
"Arousal": "0,2297",
"Gender": "Male",
"Age": "20 - 30",
"Beard": "None",
"Moustache": "None",
"Glasses": "Yes",
"Ethnicity": "Caucasian",
"Y - Head Orientation": "-1,7628",
"X - Head Orientation": "2,5652",
"Z - Head Orientation": "-3,0980",
"Landmarks": "375,4739 - 121,6879 - 383,2627 - 113,6502 - 390,8202 - 110,3507 - 396,1021 - 109,7039 - 404,9615 - 110,9594 - 443,2603 - 108,9765 - 451,9454 - 106,7192 - 457,1207 - 106,8835 - 464,1162 - 109,5496 - 470,9659 - 116,8992 - 387,4940 - 132,0171 - 406,4031 - 130,4482 - 441,6239 - 128,6356 - 460,6862 - 128,1997 - 419,0713 - 161,6479 - 425,3519 - 155,1223 - 431,9862 - 160,6411 - 406,9320 - 190,3831 - 411,4790 - 188,7656 - 423,1751 - 185,6583 - 428,5339 - 185,6882 - 433,7802 - 184,8167 - 445,6192 - 186,3515 - 450,8424 - 187,2787 - 406,0796 - 191,1880 - 411,9287 - 193,5352 - 417,9666 - 193,6567 - 424,0851 - 193,4941 - 428,6678 - 193,5652 - 433,2172 - 192,7540 - 439,3548 - 192,0136 - 445,4181 - 191,1532 - 451,6007 - 187,9486 - 404,5193 - 190,6352 - 412,8277 - 185,4609 - 421,1355 - 181,2883 - 428,3182 - 181,1826 - 435,2024 - 180,2258 - 443,9292 - 183,2533 - 453,1117 - 187,2288 - 405,9689 - 193,2750 - 410,0249 - 199,8118 - 416,0457 - 203,0374 - 423,4839 - 204,1818 - 429,9247 - 204,2175 - 436,3620 - 203,1305 - 443,4268 - 200,9355 - 448,9572 - 197,1335 - 452,0746 - 190,0314",
"Quality": "0,8137",
"Mouth": "Closed",
"Left Eye": "Open",
"Right Eye": "Open",
"Left Eyebrow": "Lowered",
"Right Eyebrow": "Lowered",
"Identity": "NO IDENTIFICATION"
}
优化
- 请记住将正则表达式的声明(在本例中为
myregexp)移至任何循环或重复函数调用之外,以便正则表达式仅编译一次。 - 是的,可能有一种更快的方法 - 使用 jsperf.com如果你正在比较事物。
这是一个示例: http://jsperf.com/image-features-log-parsing/5
请记住,此示例每次在循环中都会编译正则表达式。
关于JavaScript 使用正则表达式解析日志条目(没有明显的分隔符),我们在Stack Overflow上找到一个类似的问题: https://stackoverflow.com/questions/34242363/