我正在使用 JavaScript 正则表达式 /(<mos>[\s\S]*?<\/mos>)/g在日志文件中查找 XML block ,大致如下所示:
Entry 1: <mos>...</mos>
Entry 2: <mos>...</mos>
但是,有时日志记录过程会遇到错误并且未完成向文件写入条目,在这种情况下,它看起来像这样:
Entry 1: <mos>Error!
Entry 2: <mos>...</mos>
发生这种情况时,正则表达式会匹配开头 <mos> 中的所有内容。条目 1 中的标签到结束 </mos>条目 2 中的标记会导致稍后处理 XML 时出现问题。
似乎首先以某种方式匹配结束标记,然后查找相应的开始标记可以避免这种情况,但我不知道如何做到这一点,也不知道是否可以使用正则表达式。
<小时/>澄清:...由开始和结束标记分隔的 block 中可以包含换行符。
最佳答案
这个应该适合您的需求:
<mos>((?:[\s\S](?!<mos>))+?)</mos>
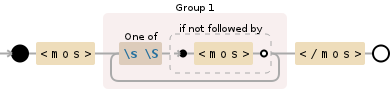
Debuggex 的可视化
RegExr 上的演示
<小时/>如果使用 JS 正则表达式文字,请不要忘记转义斜杠。
关于javascript - 正则表达式查找最小可能的匹配,我们在Stack Overflow上找到一个类似的问题: https://stackoverflow.com/questions/26102838/