问题并不是真正提取数据,而是定位数据。我正在抓取足球数据。该网站按总计(所有年份)或年份(季节)进行布局,但是 html 中包含的数据是关于所有时间的数据,而不是您选择的季节,即使该网站显示季节统计的。有趣的是,当您加载一个季节的数据时,它首先加载并简要显示该变量所有时间的数据。 例如:html 源第 983 行“td”标记内的行 for this site ,当我查看切尔西那个赛季的胜利页面时,它显示为 515(切尔西历史上的胜利次数),应该是 26 场。 谁能解释一下这个巫术以及如何按季节抓取数据?
最佳答案
看起来当您选择一个季节时,他们会从返回 JSON 格式数据的 API 中提取数据。这使您的工作变得更加轻松,因为 JSON 比 HTML 更容易解析。
您可以在 Chrome 网络开发工具中查看请求和响应:
- 在 Chrome 中查看页面时按 F12。
- 转到“网络”选项卡。
- 点击“过滤器”图标,然后点击“XHR”。
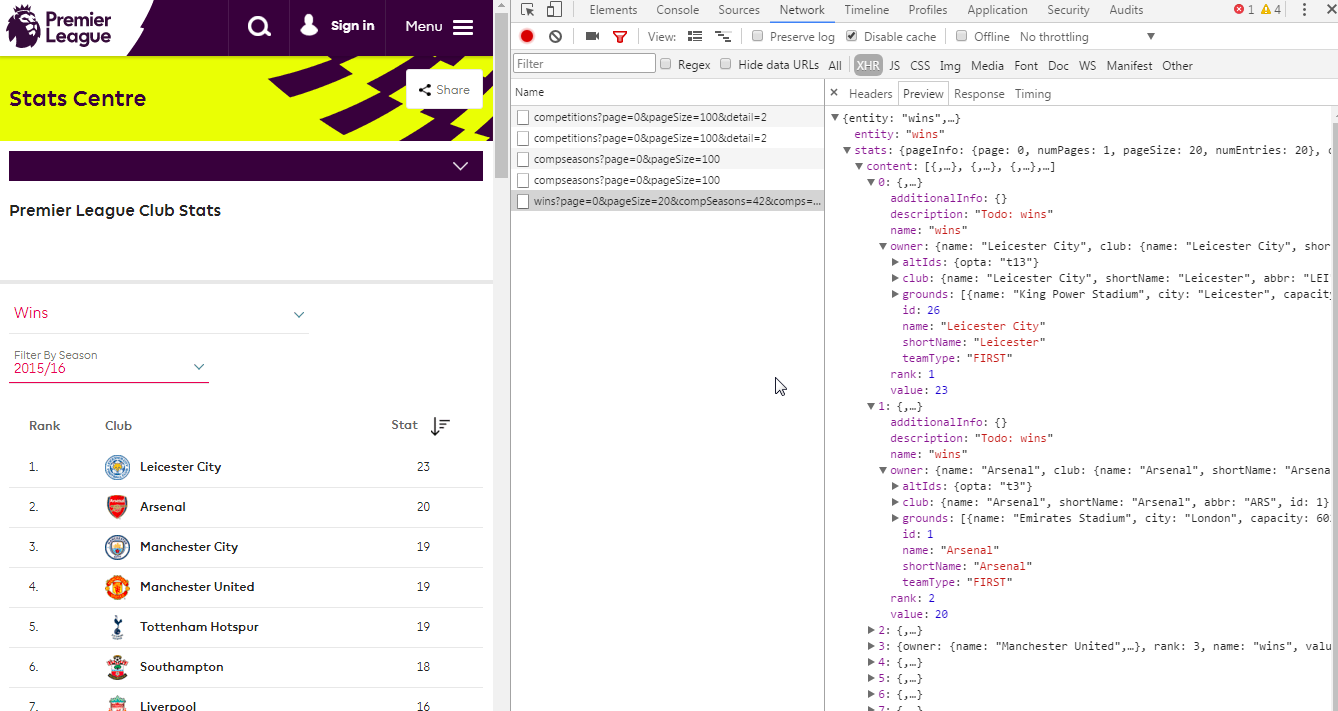
当您选择赛季时,您应该会看到向 Footballapi.pulselive.com 发出的 XHR 请求。
在开发工具中单击该 URL,然后单击右侧的“预览”选项卡以查看格式良好的响应。
我认为您将能够在程序中模仿这些请求。您可能需要发送一些相同的请求 header ,因为如果您尝试直接在浏览器中访问 API,它们似乎会阻止它。
关于javascript - 使用 Python-BeautifulSoup 和 urllib 抓取奇怪的 html 设置,我们在Stack Overflow上找到一个类似的问题: https://stackoverflow.com/questions/44080707/