我有一个任意大小的文本文件,模拟我们称为雷达的二维输出。在此输出中,我希望能够识别已知的模式。我们称之为目标检测。
目标可能看起来像这样,每个 X 都是一个亮起的像素,这意味着雷达检测到可能是敌人一部分的东西,而每个空白都是一个关闭的像素。
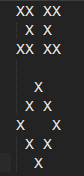
雷达数据以引入“干扰”的形式出现,也就是说,该图形不会打开所有像素。所以我正在考虑在检测中也包含某种概率。
我从未做过类似的事情,我正在寻求一般建议。我正在尝试不同的方法,我确信我会以某种方式解决它,但我真的很想有一些关于这种模式匹配的指南、阅读资源或类似的内容,因为我认为它非常有趣,但以前没有机会解决这样的问题。
有什么想法吗?
最佳答案
感知器采用一组输入的加权线性组合,并输出 1 或 0,具体取决于结果是正还是负。可以说,人工智能是通过权重来实现的,而权重决定了数据的分割。一侧结果为正,另一侧结果为负。这种分割可以被认为是图表上的一条线。例如,如果权重给出一条线 y=x,则输入 x = 2、y = 4 将为正,输入 x = -1、y = 1 将为负。通过向系统提供正负输入集并调整权重直到训练集的输出与所需输出匹配来训练权重。
输入数量由像素数量给出,每个像素都有自己的输入和关联的权重,因此权重是与图像大小相同的数组。
对于您的示例,您需要一组敌人目标的图像,其中一些图像具有预期的噪声。这些的期望输出将为正,因此将所有图像呈现给感知器并检查输出。如果输出不为 1,则调整权重。接下来显示非敌人图像并检查输出是否为 0。如果不是,则调整权重。继续显示正图像并检查输出是否为 1,负图像检查输出是否为 0,调整权重,直到获得输出。
最初,权重设置为小的随机数。如果实际输出与期望输出不匹配(一开始就不匹配),请通过以下公式调整每个权重:
w(t+1) = w(t) + a(d-y)x
因此,新权重是旧权重加上 alpha 乘以所需输出减去实际结果乘以输入(对于该像素)
Alpha 可以随着训练的进行而改变。首先它很大,所以收敛速度很快。随着时间的推移,最好减少数量以减慢收敛速度,从而更加准确。 Alpha,学习率应该为0
所以在 Java 中:
创建一个权重数组并将其初始化为小的随机数。
创建一组输入图像和相应的所需输出。
选择一个随机图像并将其呈现给系统。 - 将输入乘以权重,求和并找到符号。
根据期望的输出检查输出。如果它们相同,则选择另一个输入图像。如果存在差异,则通过方程调整权重,然后选择另一个输入图像。
继续显示输入,直到总误差低于某个阈值。
当系统经过训练时,可以向系统呈现看不见的图像。如果是敌方目标,则输出 1,如果不是 0,则输出 1。
所有详细信息都可以在线找到,维基页面,还有更多解释,但希望它有所帮助。
关于java - 识别文本文件中的 "figure"模式,我们在Stack Overflow上找到一个类似的问题: https://stackoverflow.com/questions/12663727/