我的程序解析一行文本。在下图中,我在来自 Tesseract 结果迭代器的每个字符周围绘制了边界框:
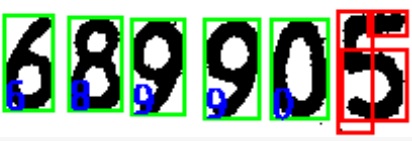
显然,Tesseract 在分割行中最后一个字符(“5”)、检测 3 个边界框时存在一些问题。 事实上,最后一个字符比其他字符稍大一些,但是当像素点阈值设置得如此清晰时,为什么 Tesseract 会以如此不同的方式对该字符进行分割呢?
我已经设置了这些 Tesseract 变量:
tess.setVariable("save_blob_choices", "1");
tess.setPageSegMode(PageSegMode.PSM_SINGLE_LINE);
tess.setVariable(TessBaseAPI.VAR_CHAR_WHITELIST, "0123456789"
and textord_min_xheight set to the pixel height of the above image
有什么建议吗?
最佳答案
我没有找到解决这个问题的方法。 Tesseract 的文档记录非常糟糕。
我最终找到了每个字符的轮廓,然后将字符的每个子图像传递给 Tesseract,使用页面分割模式 PSM_SYMBOL。最后,这也比之前的方法快了一倍!
关于java - 超立方体边界框问题,我们在Stack Overflow上找到一个类似的问题: https://stackoverflow.com/questions/20483111/