最近我在使用 R 时遇到了类似的问题,现在我想在 python 2.7 中使用 pandas 来完成此操作。我在这里审查了几个类似的问题,但可惜仍然有问题。
我有两个数据框:
import pandas as pd
dfa = pd.DataFrame([["1", "1", "2", "A"], ["2", "1", "2", "A"], ["3", "3",
"4", "B"], ["4", "3", "4", "B"], ["5", "5", "6", "C"], ["6", "5", "6",
"C"], ["7", "7", "8", "D"], ["8", "7", "8", "D"]], columns=['TimeStamp',
'Min', 'Max', 'Group'])
dfb = pd.DataFrame([['1'], ['2'], ['3'], ['4'], ['5'], ['6'], ['7'], ['8']],
columns = ['TimeStamp'])
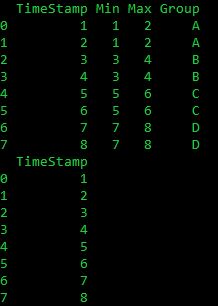
我正在寻找一种基于时间戳在 dfb 中创建组 ID 的方法,该时间戳落在 dfa 中每个组的最小-最大范围内。所以,dfb_final:
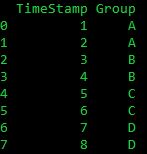
这适用于较大的数据集,我简化了示例。我只是不太确定下一步该做什么。我根据其他答案获得了 dfa 中的最小最大列。非常感谢向大家学习。
最佳答案
您可以使用np.searchsorted 。以下解决方案假设各组之间的 Min/Max 值没有重叠。首先将一些系列转换为数字,以便可以通过 NumPy 使用它们:
dfa[dfa.columns[:-1]] = dfa[dfa.columns[:-1]].apply(pd.to_numeric)
dfb['TimeStamp'] = pd.to_numeric(dfb['TimeStamp'])
注意,如有必要,日期时间/时间戳值可以转换为等价数字。
然后提取唯一组和 Min/Max 值的扁平版本:
groups = dfa['Group'].unique()
vals = dfa.drop_duplicates('Group').loc[:, ['Min', 'Max']].values.ravel()
最后,使用 np.searchsorted 在 vals 中定位时间戳,并使用结果为 groups 建立索引:
dfb['Group'] = groups[np.searchsorted(dfb['TimeStamp'].values, vals) // 2]
print(dfb)
TimeStamp Group
0 1 A
1 2 A
2 3 B
3 4 B
4 5 C
5 6 C
6 7 D
7 8 D
关于python - 根据另一个数据帧的组范围解释数据帧列的范围,我们在Stack Overflow上找到一个类似的问题: https://stackoverflow.com/questions/52864594/