这是我想要的输出:

我正在尝试计算列 df[Value] 和 df[Value_Compensed]。但是,为此,我需要考虑行 df[Value_Compensed] 的先前值。就我的表格而言:
- 第一行所有值都是0
- 以下行:
df[Remained] = 先前的 df[Value_compensed]。然后df[Value] = df[Initial_value] + df[Remained]。然后df[Value_Compensed] = df[Value] - df[Compensation]
...等等...
我正在努力将 Value_Compensed 的值从一行传递到下一行,我尝试使用函数 shift(),但如下图所示,df[Value_Compensed] 中的值不正确,因为它不是静态值,并且在每行不起作用后它也会发生变化。有什么想法吗??
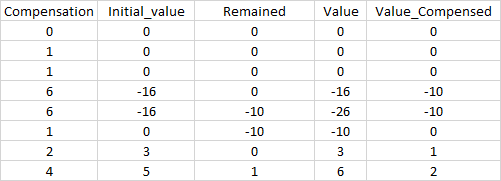
谢谢。
曼努埃尔.
最佳答案
您可以使用apply创建您的定制操作。由于您没有提供初始数据框,我制作了一个虚拟数据集。
from itertools import zip_longest
# dummy data
df = pd.DataFrame(np.random.randint(1, 10, (8, 5)),
columns=['compensation', 'initial_value',
'remained', 'value', 'value_compensed'],)
df.loc[0] = 0,0,0,0,0
>>> print(df)
compensation initial_value remained value value_compensed
0 0 0 0 0 0
1 2 9 1 9 7
2 1 4 9 8 3
3 3 4 5 7 6
4 3 2 5 5 6
5 9 1 5 2 4
6 4 5 9 8 2
7 1 6 9 6 8
使用 apply (axis=1) 进行逐行迭代,其中使用初始数据帧作为参数,然后可以从中获取上一行x.name- 1 并进行计算。不确定我是否完全理解预期结果,但您可以调整函数中不同列的单独计算。
def f(x, data):
if x.name == 0:
return [0,]*data.shape[1]
else:
x_remained = data.loc[x.name-1]['value_compensed']
x_value = data.loc[x.name-1]['initial_value'] + x_remained
x_compensed = x_value - x['compensation']
return [x['compensation'], x['initial_value'], x_remained, \
x_value, x_compensed]
adj = df.apply(f, args=(df,), axis=1)
adj = pd.DataFrame.from_records(zip_longest(*adj.values), index=df.columns).T
>>> print(adj)
compensation initial_value remained value value_compensed
0 0 0 0 0 0
1 5 9 0 0 -5
2 5 7 4 13 8
3 7 9 1 8 1
4 6 6 5 14 8
5 4 9 6 12 8
6 2 4 2 11 9
7 9 2 6 10 1
关于python - 如何在 pandas + python 中将值从一行传递到下一行,并使用它递归计算相同的后续值,我们在Stack Overflow上找到一个类似的问题: https://stackoverflow.com/questions/55944027/