我在网络抓取过程中一直遇到一个问题,即收到空字符串而不是预期结果(基于检查页面 html)。
我的具体目标是从 https://www.twitch.tv/directory/game/Overwatch/clips?range=7d 获取前 10 个剪辑的链接.
这是我的代码:
# Gathers links of clips to download later
import bs4
import requests
from selenium import webdriver
from pprint import pprint
import time
from selenium.webdriver.common.keys import Keys
# Get links of multiple clips by webscraping main_url
main_url = 'https://www.twitch.tv/directory/game/Overwatch/clips?range=7d'
driver = webdriver.Firefox()
driver.get(main_url)
time.sleep(10)
elements_found = driver.find_elements_by_class_name("tw-interactive tw-link tw-link--hover-underline-none tw-link--inherit")
print(elements_found)
driver.quit()
This is how I decided on the class name
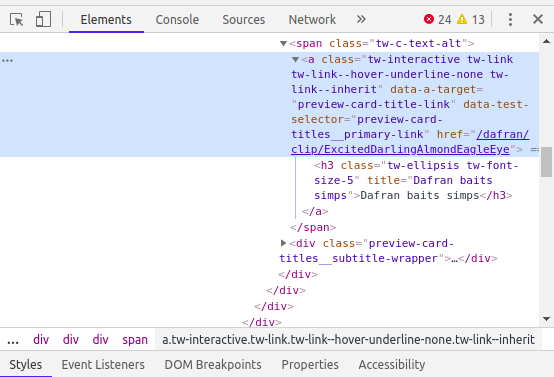{kind=link}
该页面使用 Javascript,这就是我在请求模块上使用 Selenium 的原因(我尝试过,但没有成功)。
我添加了time.sleep(10),以便我有时间滚动网页来激活java脚本,但没有效果。
我还尝试过更改用户代理和使用 XPath,这两种方法都没有产生不同的结果。
无论我做什么,程序似乎只查看通过右键单击 -> 检查页面源代码找到的原始 html。
任何帮助和指示将不胜感激,我觉得自己完全陷入了这个问题。我在 Automate the Boring Stuff 的“第 11 章:Webscraping”的所有项目以及我的个人项目中都遇到了这些问题。
最佳答案
find_elements_by_class_name 仅接收一个类作为参数,因此 elements_found 是一个空列表。例如
find_elements_by_class_name('tw-interactive')
您正在使用 4 个类。为此,请使用 css_selector
elements_found = find_elements_by_css_selector('.tw-interactive.tw-link.tw-link--hover-underline-none.tw-link--inherit')
或者明确
elements_found = find_elements_by_css_selector('[class="tw-interactive tw-link tw-link--hover-underline-none tw-link--inherit"]')
要从元素中获取 href 属性,请使用 get_attribute()
for element in elements_found:
element.get_attribute('href')
关于python - 如何使用 Selenium 和 Python 从 https ://www. twitch.tv/directory/game/Overwatch/clips?range=7d 中抓取前 10 个剪辑的 href 属性,我们在Stack Overflow上找到一个类似的问题: https://stackoverflow.com/questions/59452460/