我试图从包含阿拉伯语句子的 csv 文件中删除停用词,但我不确定是否有很多错误
我的代码
print(tokenized_docs_no_punctuation)
stops = set(stopwords.words('arabic'))
words=tokenized_docs_no_punctuation
print([word for word in words if word not in stops])
这是错误
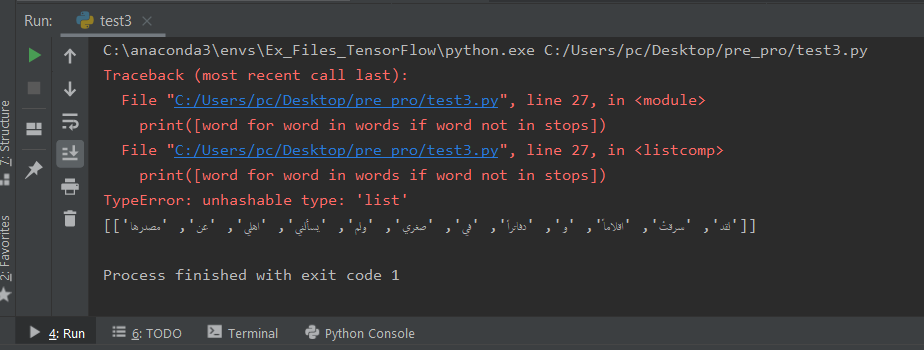
有什么想法或解决方案吗?
最佳答案
您收到的错误 TypeError: unhashable type: 'list' 表明您正在尝试对 list 对象进行哈希处理。根据您在问题中发布的代码,似乎 set(stopwords.words('arabic')) 导致了错误,因为 set 函数尝试散列参数以查找重复。查看 stopwords.words('arabic') 输出并确保输出中没有 list 对象。
关于python 3解决数据框问题,我们在Stack Overflow上找到一个类似的问题: https://stackoverflow.com/questions/59452678/