我正在尝试从文件中提取文本的特定部分。 我无法使正则表达式匹配尽可能少的字符。
这是一个示例文本文件。
UNIQUE
sdkjbskdfb....
UNIQUE
lnasdljnkjn......
UNIQUE
*Text from here is needed*
UNIQUE2
*Text from here is needed*
UNIQUE
我最大的努力就是这个。 “UNIQUE(.\*?)UNIQUE2(.\*?)UNIQUE”
不幸的是,这与整个内容匹配,因为它使用第一个 UNIQUE 值而不是第三个值。
最佳答案
您需要负向前瞻:
UNIQUE((?:(?!UNIQUE).)*?)UNIQUE2(.*?)UNIQUE
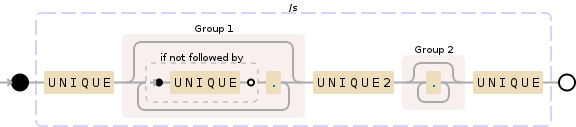
这就是说,在您点击 UNIQUE2 之前,先找到 UNIQUE 后跟一些不包含 UNIQUE 的字符串,等等。
如果您需要澄清,请告诉我。
关于python - python中的正则表达式匹配,我们在Stack Overflow上找到一个类似的问题: https://stackoverflow.com/questions/22317256/