我正在尝试解析表单的标记-
!TAG1 VAL1=0.88 VALARRAY=0. 0. 0.8 !TAG2 VAL2=0.998 !END !END'
就标记而言,我知道这是一种相当糟糕的表示不带引号的真实向量的方法。但它是在我正在处理的旧代码中解析的,我不想更改“标准”输入格式。
我已经实现了一个 do while 循环来解析它 - 程序逐字遍历字符串(单词=不包含空格)和两个计数器 - 一个坚持具有最后一个 =< 的单词位置 ,第二个寻找下一个包含 = 的单词。对于一个可以咀嚼每个 VAR=VALUE 对的Pythonic 迭代器有什么想法吗?
EDIT1:这是我的解决方案,尽管我经过多次迭代才找到它。因此它的可读性不是很好!
s1='!TAG1 VAL1=0.88 VALARRAY=0. 0. 0.8 !TAG1 VAL2=0.998 !END !END'
list=[]
word=''
for s in s1.split():
if (s[0]=='!'):
if word : list.append(word)
list.append(s)
word=''
else :
if '=' in s:
if word : list.append(word)
word=s
else:
word=(word+" "+s).strip()
if word: list.append(word)
print s1
print list
输出是-
!TAG1 VAL1=0.88 VALARRAY=0. 0. 0.8 !TAG1 VAL2=0.998 !END !END
['!TAG1', 'VAL1=0.88', 'VALARRAY=0. 0. 0.8', '!TAG1', 'VAL2=0.998', '!END', '!END']
希望这有帮助!
最佳答案
说明:
(?# capture valueless keys)
! (?# match !)
( (?# start capturing group)
\S+ (?# match non-whitespace characters)
) (?# end capturing group)
| (?# OR)
(?# capture key/value pairs)
( (?# start capturing group)
\S+? (?# lazily match non-whitespace)
) (?# end capturing group)
= (?# match literal =)
( (?# start capturing group)
[^=]+? (?# lazily match anything but =)
) (?# end capturing group)
(?# values have a loose definition, so we need to lookahead for a delimiter)
(?= (?# start lookahead)
\s* (?# match optional whitespace)
(?: (?# start non-capturing group)
\S+?= (?# match another key)
| (?# OR)
!\S+ (?# match another key w/o value)
| (?# OR)
$ (?# match end of the string)
) (?# end non-capturing group)
) (?# end lookahead)
可视化:
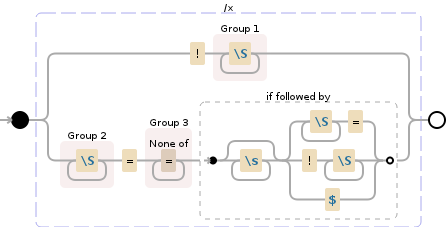
注释:
您的无值键 (!TAG) 将位于第一个捕获组中,键/值对 (VAL1=0.88) 将位于第二/第三个捕获组中分别捕获组。无值键很简单,只需匹配 !,然后捕获任何非空白字符 (\S = [^\r\n\t\f ])。键/值对更困难,我们从非空白字符开始,然后是 =,然后是任何非 = (OP 提到的没问题)。但是,我们需要一种方法来阻止这些值继续到字符串末尾。因此,我们将其设为惰性匹配,然后向前查找空格,后跟:另一个键/值、另一个无值键或字符串末尾。
我们不要忘记缩小版本;)
!(\S+)|(\S+?)=([^=]+?)(?=\s*(?:\S+?=|!\S+|$))
关于python - 解析输入标记,我们在Stack Overflow上找到一个类似的问题: https://stackoverflow.com/questions/23637174/