我有三个数组(或列表,或其他):
x - 横坐标。一组分布不均匀的数据。
y - 纵坐标。一组数据代表y=f(x) .
peaks - 元素包含有序对 (x,y) 的一组数据,代表 y 中找到的峰值.
这是 x 的一部分和y数据:
2.00 1.5060000000e-07
...
...
5.60 3.4100000000e-08
5.80 1.7450000000e-07
6.00 7.1700000000e-08
6.20 5.2900000000e-08
6.40 2.5570000000e-07
6.50 4.8420000000e-07
6.60 6.1900000000e-08
6.80 2.2700000000e-07
7.00 2.3500000000e-08
7.20 3.6500000000e-08
7.40 1.0158000000e-06
7.50 3.5100000000e-08
7.60 2.0080000000e-07
7.80 1.6585000000e-06
8.00 2.1190000000e-07
8.20 5.3370000000e-07
8.40 5.7840000000e-07
8.50 4.5230000000e-07
...
...
50.00 1.8200000000e-07
这里是print(peaks) :
[(3.7999999999999998, 4.0728000000000002e-06), (5.4000000000000004, 5.4893000000000001e-06), (10.800000000000001, 1.2068e-05), (12.699999999999999, 4.1904799999999999e-05), (14.300000000000001, 8.3118000000000006e-06), (27.699999999999999, 6.5239000000000003e-06)]
我使用数据绘制图表,类似于:
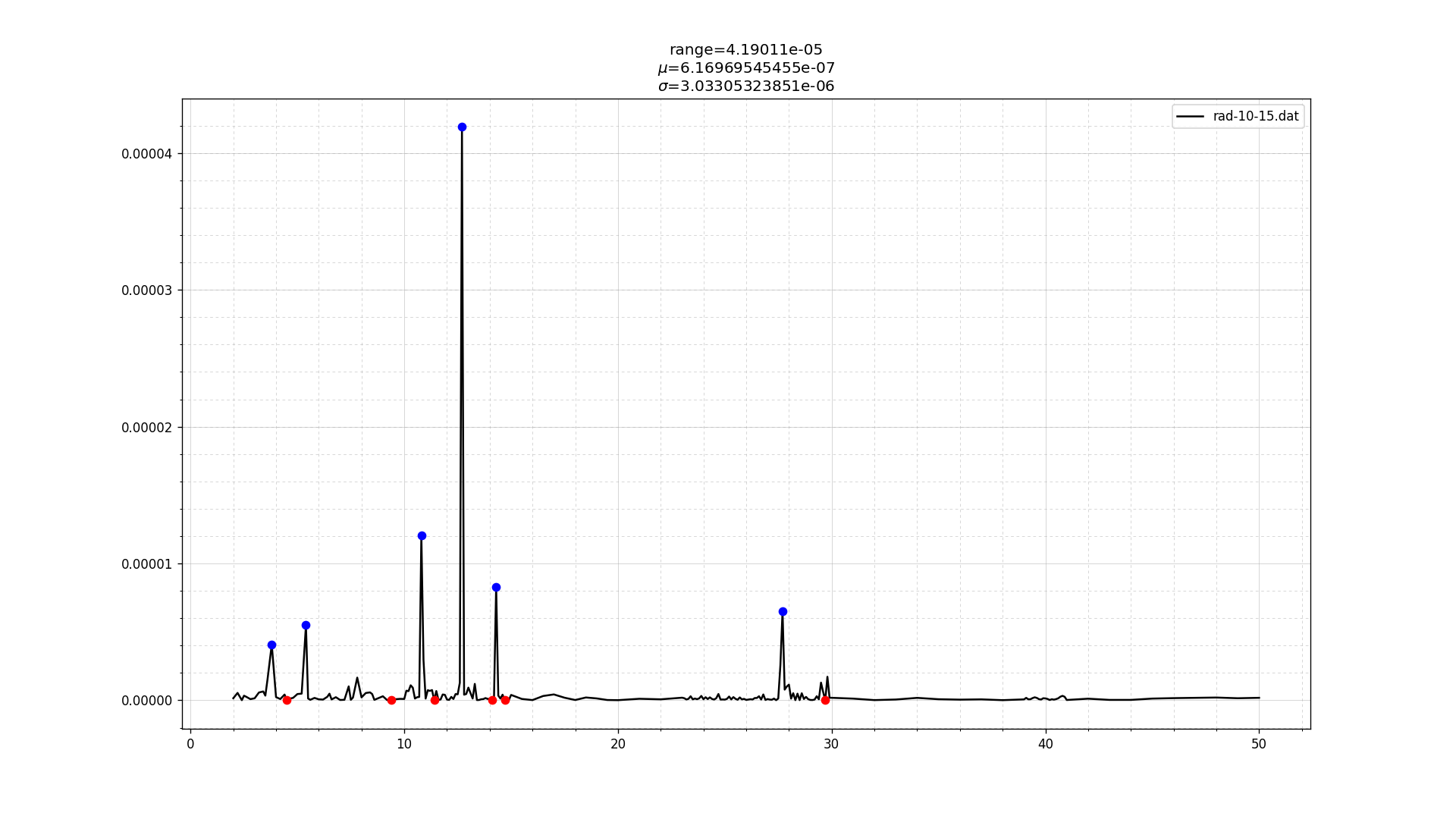
图中的蓝点是峰值。红点是山谷。但红点不一定准确。您可以看到最后一个峰值的右侧有一个红点。这不是有意的。
使用上面的数据,我尝试按如下方式找到山谷:
浏览peaks数组(或列表,或无论它是什么),对于每对相邻的峰值,在 x 中找到它们的索引和y数组(或列表,或无论它们是什么),然后搜索 y由这些索引绑定(bind)的最小值的数组。还找到对应的x该指数的值。然后附加 (x,y)与数组配对 v1 (或列表,或其他),就像 peaks 。然后绘制v1作为红点。
这是代码:
for i in xrange(1,len(peaks)):
# Find the indices of the two peaks in the actual arrays
# (e.g. x[j1] and y[j1]) where the peaks occur
j1=np.where(x==peaks[i-1][0])
j1=int(j1[0])
j2=np.where(x==peaks[i][0])
j2=int(j2[0])
# In the array y[j1:j2], find the index of the minimum value
j=np.where(y==min(y[j1:j2]))
# What if there are more than one minumum?
if(len(j[0])>1):
# Use the first one.
# I incorrectly assumed this would be > j1,
# but it could be anywhere in y
jt=int(j[0][0])
v1.append((x[jt],y[jt]))
# And the last one.
# I incorrectly assumed this would be < j2,
# but it could be anywhere in y. But we do know at least one of the
# indices found will be between j1 and j2.
jt=int(j[0][-1])
v1.append((x[jt],y[jt]))
else:
# When only 1 index is found, no problem: it has to be j1 < j < j2
j=int(j[0])
v1.append((x[j],y[j]))
问题是这样的:
当我搜索 y 的最小值时在一定范围内,如下所示:
j=np.where(y==min(y[j1:j2]))
它返回 y 整个数据集中那些最小值的索引。但我想要j仅包含 j1 之间的最小值的索引和j2 ,我搜索过的地方。
如何限制搜索?
我可以检查是否 j1 < j < j2,但如果可能的话,我更愿意限制搜索仅返回该范围内的 j 值。
一旦我弄清楚了这一点,如果峰值超过宽度 w,我将添加逻辑来限制索引。分开。
因此,如果峰值超过 w分开,然后j1将不少于j2-w/2 ,其中j2是峰值的索引。
最佳答案
您可以先对数组进行切片,然后与切片进行 == 比较:
sliced_y = y[j1:j2]
j = np.where(sliced_y == min(sliced_y))[0] + j1
您需要+下限,否则您只有相对于切片部分的“索引”。
关于Python 在数组/列表中查找数据索引,但有约束,我们在Stack Overflow上找到一个类似的问题: https://stackoverflow.com/questions/43656966/