所以我有一个具有以下格式的 Excel 工作表:
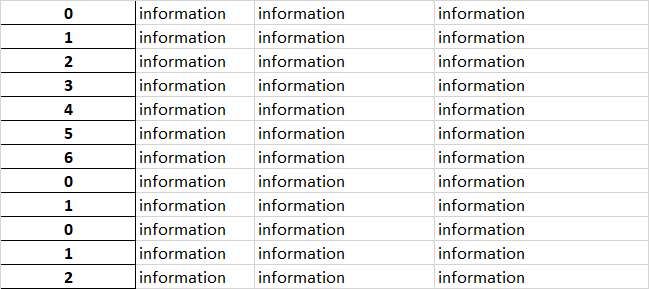
现在我要做的是循环遍历 A 列中的每个索引单元格,并为所有单元格分配相同的值,直到达到下一个 0。例如:
现在我尝试将 Excel 文件导入 pandas 数据框,然后使用 for 循环来执行此操作,但我似乎无法使其工作。任何有关适当方法的建议或指示将不胜感激! 感谢您的宝贵时间
编辑:
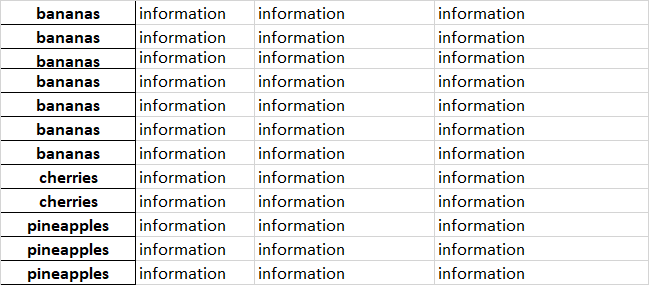
使用@wen-ben的方法:s.index=pd.Series((s.index==0).cumsum()).map({1:'bananas',2:'cherries',3:'菠萝'})
只需输入 A 列中所有单元格的第一个元素(香蕉)
最佳答案
假设您有使用 cumsum 的数据帧 s
s.index=pd.Series((s.index==0).cumsum()).map({1:'bananas',2:'cherries',3:'pineapples'})
关于python:循环遍历Excel中的索引并用字符串替换,我们在Stack Overflow上找到一个类似的问题: https://stackoverflow.com/questions/55080409/