我的数据如下所示
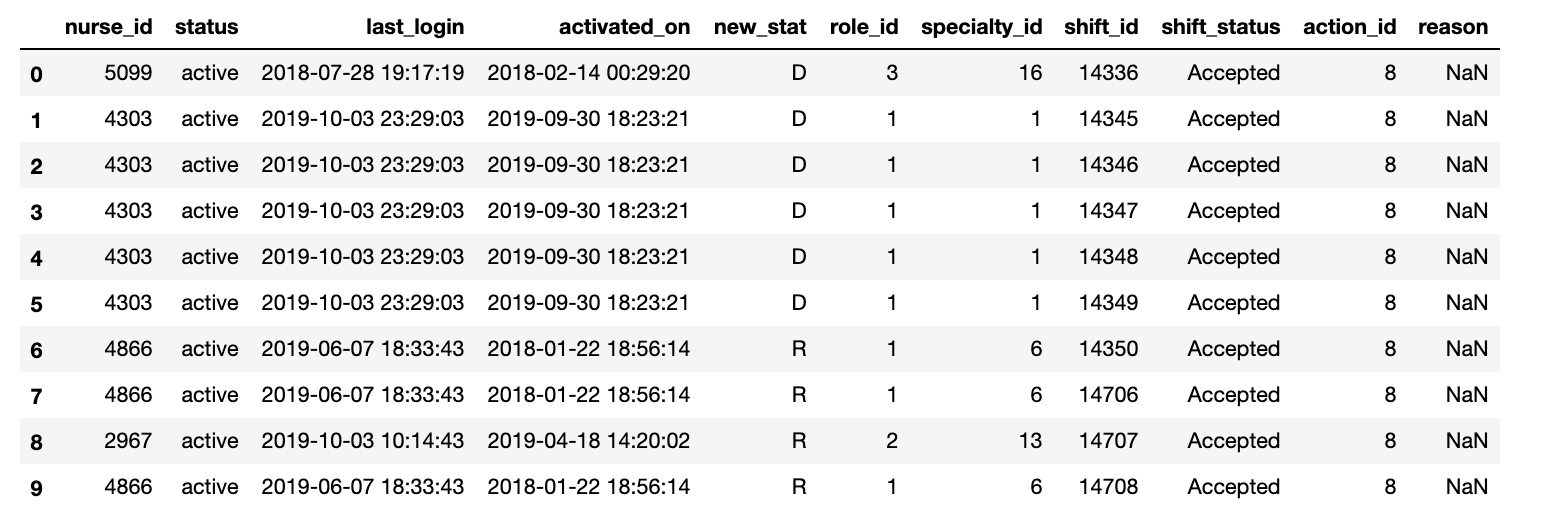
同一用户可以有多个类次 ID。因此,在护士_id 列中,我有重复的 ID。
我想在 new_state 上为独特的护士创建计数器。
目前当我这样做时
Counter(df["new_stat"])
它给出了
Counter({'D': 15123, 'R': 29300, 'not_active': 2581, 'N': 21455})
但它也会计算 ID 的重复值。
如何在 new_stat 上创建计数器独特nurse_id ?
最佳答案
Pandas 的解决方案是 SeriesGroupBy.value_counts :
df.groupby('nurse_id')['new_stat'].value_counts().reset_index(name='count')
df.groupby(['nurse_id','new_stat']).size().reset_index(name='count')
如果需要每组的计数器对象,可以使用带有 Series 构造函数的字典理解:
pd.Series({k: Counter(v['new_stat']) for k, v in df.groupby('nurse_id')})
关于python - 将计数器应用于 pandas 的唯一列值,我们在Stack Overflow上找到一个类似的问题: https://stackoverflow.com/questions/58235704/