这更像是一个应用数学/算法问题,而不是一个编码问题,但当我试图在 sklearn 中解决它时,这似乎是一个提问的好地方。
我正在编写一个用于自定义压缩格式的纹理压缩器。它存储每个纹素 block 的少量颜色端点以及这些端点的线性加权组合,以恢复每个纹素的特定值。实现此类压缩器的标准方法是使用 PCA 找到主导轴,因此您的端点是该线两端的数据点,然后沿 PCA 轴插值以获得颜色。
该格式支持多个分区 - 每个分区都有自己的颜色端点,数据 block 中的纹素可以分配给任何单个分区。将纹素分配给分区的一个常见技巧是在颜色值上使用 kmeans 聚类,但这往往会聚类像素“ Blob ”(下图中的红色圆圈),这与压缩方案的方式并不能很好地匹配想要对数据进行编码。
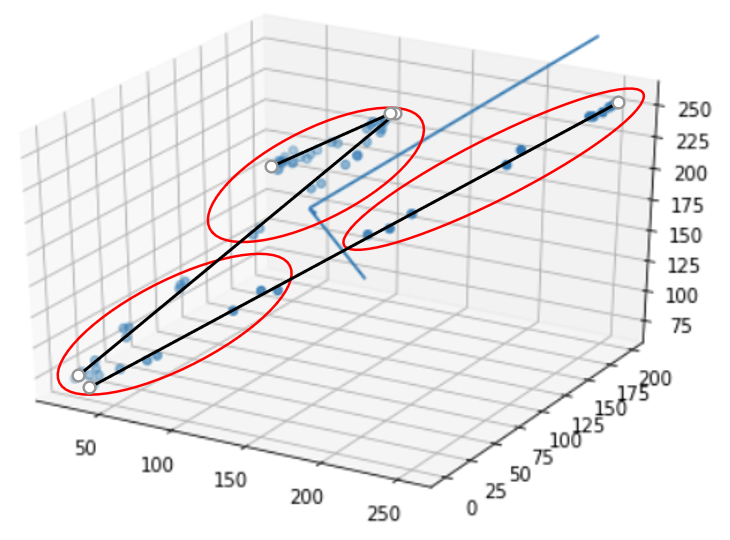 在此示例中,您可以直观地看到数据中实际上存在三“行”数据点(以黑色显示)。这些将是算法的理想选择 - 至少在测试它们是否可以以更好的质量进行编码方面 - 因为对线段的良好拟合意味着两个端点之间的良好拟合线性插值。
在此示例中,您可以直观地看到数据中实际上存在三“行”数据点(以黑色显示)。这些将是算法的理想选择 - 至少在测试它们是否可以以更好的质量进行编码方面 - 因为对线段的良好拟合意味着两个端点之间的良好拟合线性插值。
是否有任何标准算法可以围绕线拟合而不是空间聚类进行这种数据点聚类?
最佳答案
一个有趣的问题! and a field I've dabbled in .
我觉得它可能与 "Texture Compression with Adaptive Block Partitions" by Levkovich-Maslyuk, Kalyuzhny, and Zhirkov 有关。 。特别是请查看图 1。
他们的系统似乎在独立的小块(即 8x8)上工作,因此搜索空间保持合理的范围。如果您打算做同样的事情,那么也许他们的算法可能仍然适用。
如果没有,例如你的“线性集”可以在整个纹理的任何地方使用,那么我怀疑他们的方法是否可行。
[免责声明:我自己没有尝试过以下操作]
也许您仍然可以使用类似 VQ 的方法,但是,您不能存储 2 种颜色,而不是使用单一颜色作为每个子组的代表(正如您所说,这会导致“ Blob ”),即定义线段? IE。而不是让“k-means”具有“k-segments”?
显然,你的“最佳拟合”是距线段的距离,所有最接近颜色的“平均”步骤就是 PCA 算法。
当你想产生新的候选人时你该怎么做并不那么清楚。也许如果您想要 N 个,您可以简单地从一组随机的 N 个候选开始,然后重复应用最佳拟合和重新映射算法。
或者,也许每次迭代都可以找到最差匹配的像素来生成新的候选像素。
在我看来,其中一个值得研究。
我很好奇的是您计划使用多少位来混合端点以及如何确定要使用哪个段。
关于python - PCA 线拟合聚类算法,我们在Stack Overflow上找到一个类似的问题: https://stackoverflow.com/questions/58896211/