我熟悉使用 Scrapy 抓取网站,但我似乎无法抓取 this一个(也许是javascript?)。
我正在尝试从此网站下载商品的历史数据以进行一些个人研究: http://www.mcxindia.com/SitePages/BhavCopyDateWiseArchive.aspx
在此网站上,您必须选择日期,然后单击“开始”。数据加载后,您可以单击“在 Excel 中查看”下载包含当天商品价格的 CSV 文件。我正在尝试构建一个抓取工具来下载这些 CSV 文件几个月。然而,这个网站似乎很难破解。任何帮助将不胜感激。
我尝试过的事情: 1)查看页面源码,看看数据是否正在加载但未显示(隐藏) 2)使用firebug查看是否有AJAX请求 3) 修改 POST header 以查看是否可以获得不同日期的数据。帖子标题看起来很复杂。
最佳答案
众所周知,Asp.net 网站很难抓取,因为它依赖 viewsessions ,对请求和大量其他废话极其严格。
幸运的是,您的情况似乎非常简单。你的 scrapy 方法应该类似于:
import scrapy
from scrapy import FormRequest
class MxindiaSpider(scrapy.Spider):
name = "mxindia"
allowed_domains = ["mcxindia.com"]
start_urls = ('http://www.mcxindia.com/SitePages/BhavCopyDateWiseArchive.aspx',)
def parse(self, response):
yield FormRequest.from_response(response,
formdata={
'mTbdate': '02/13/2015', # your date here
'ScriptManager1': 'MupdPnl|mImgBtnGo',
'__EVENTARGUMENT': '',
'__EVENTTARGET': '',
'mImgBtnGo.x': '12',
'mImgBtnGo.y': '9'
},
callback=self.parse_cal, )
def parse_cal(self, response):
inspect_response(response, self) # everything is there!
我们在这里所做的是创建 FormRequest来自response我们已经拥有的对象。它足够聪明,可以找到 <input>和<form>字段并生成表单数据。
然而,一些没有默认值或我们需要覆盖默认值的输入字段需要用 formdata 覆盖。争论。
所以我们提供formdata具有更新的表单值的参数。当您检查请求时,您可以看到成功请求所需的所有表单值:
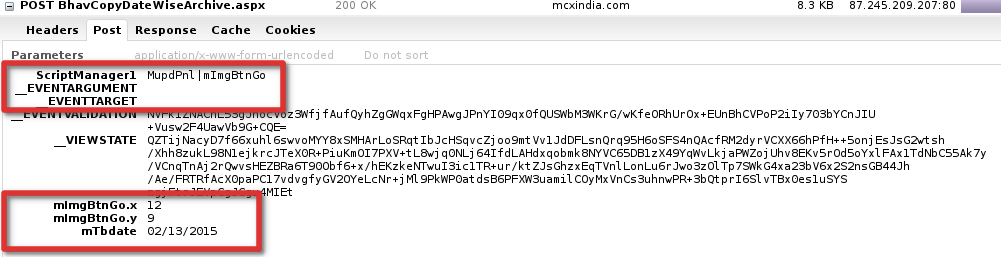
所以只需将它们全部复制到您的 formdata 中即可。 Asp 确实对表单数据很挑剔,因此需要花一些时间来试验什么是必需的,什么不是。
我会让你自己弄清楚如何进入下一页,通常它只是向 formadata 添加附加 key 喜欢 'page': '2' .
关于python - Scrapy - Javascript 网站,我们在Stack Overflow上找到一个类似的问题: https://stackoverflow.com/questions/35424535/