我有一个 CSV 文档,其中有一列,其中每个单元格都包含一个字典列表。任何有关如何提取该数据同时将其保留为字典列表的建议将不胜感激。我已经尝试了通常的 json/pandas/csv 读入,但它们似乎都无法正常工作(转换为字符串/unicode,这并不奇怪,但仍然令人沮丧)。最终,我希望输出是一个数据框,其中标题行是键,后面的每一行是数据。
示例 CSV 部分:
1 results
2 [{"y": 47, "type": "square"}, {"type": "square", "b": 49}, {"type": "square", "z": 29}, {"a": 69, "type": "square"}, {"type": "square", "x": 81}]
3 [{"type": "circle", "b": 90}, {"y": 12, "type": "circle"}, {"a": 78, "type": "circle"}, {"type": "circle", "c": 74}, {"type": "circle", "x": 14}, {"type": "circle", "z": 19}]
4 [{"type": "square", "b": 85}, {"type": "square", "x": 73}, {"type": "square", "c": 50}]
5 [{"type": "triangle", "c": 71}, {"type": "triangle", "z": 66}, {"type": "triangle", "x": 16}, {"type": "triangle", "b": 38}, {"y": 67, "type": "triangle"}, {"a": 80, "type": "triangle"}]
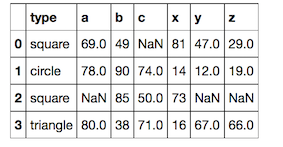
示例输出:
type a b c x y z
0 square 69 49 NaN 81 47 29
1 circle 78 90 74 14 12 19
2 square NaN 85 50 73 NaN NaN
3 triangle 80 38 71 16 67 66
最佳答案
评估文件中的每一行并进行一些字典工作可以获得所需的结果:
with open(filename) as fobj:
next(fobj) # skip first line with word `results`
data = [eval(line) for line in fobj if line.strip()]
res = []
for entry in data:
d = entry[0].copy()
for x in entry[1:]:
d.update(x)
res.append(d)
df = pd.DataFrame(res)
df.reindex_axis(['type', 'a', 'b', 'c', 'x', 'y', 'z'], axis=1)
df
如果您不需要这些行上的文本。您可以删除 [] 之外的所有内容:
eval('[' + line.split('[')[-1].split(']')[0] + ']')
或者,您可以使用正则表达式:
import re
eval(re.findall(r'\[.*?\]', line)[0])
关于python - CSV 中的字典列表,我们在Stack Overflow上找到一个类似的问题: https://stackoverflow.com/questions/41382896/