从现有 docx 读取和写入新 docx 时保留表格格式
这是我为 demo.docx 中的下表尝试的代码
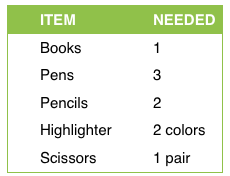
but I am not getting the output in same format Need help to fix this so that I can copy this table in the same format to my new docx
ITEM
NEEDED
Books
1
Pens
3
Pencils
2
Highlighter
2 colors
Scissors
1 pair
我正在使用的代码如下..
import docx
doc = docx.Document('demo.docx')
doc = docx.Document('demo.docx')
for table in doc.tables:
for row in table.rows:
for cell in row.cells:
for para in cell.paragraphs:
print para.text
我正在经历Parsing of table from .docx file但同样,我需要在新的 docx 中创建表,不知道该怎么做。
最佳答案
我认为我有一种笨拙的方法,首先将原始 docx 表转换为 pandas DataFrame,然后将数据帧添加回新文档。
据我所知,文档文件(*.docx、*.doc、*.txt)作为字符串读取,因此我们必须将数据视为字符串。这意味着您需要知道表格的列数和行数。
假设原始文档文件名为“Stationery.docx”,这可能会成功。
import docx
import pandas as pd
import numpy as np
doc = docx.Document("Stationery.docx")
df = pd.DataFrame()
tables = doc.tables[0]
##Getting the original data from the document to a list
ls =[]
for row in tables.rows:
for cell in row.cells:
for paragraph in cell.paragraphs:
ls.append(paragraph.text)
def Doctable(ls, row, column):
df = pd.DataFrame(np.array(ls).reshape(row,column)) #reshape to the table shape
new = docx.Document()
word_table =new.add_table(rows = row, cols = column)
for x in range(0,row,1):
for y in range(0,column,1):
cell = word_table.cell(x,y)
cell.text = df.iloc[x,y]
return new, df
关于python - 使用Python从docx解析表,我们在Stack Overflow上找到一个类似的问题: https://stackoverflow.com/questions/52307081/