我正在尝试使用正则表达式模块编写一小段代码,该模块将从 .csv 文件中删除 URL 的一部分,并返回选定的 block 作为输出。如果该部分以 .com/go/结尾,我希望它在“go”之后返回内容。代码如下:
import csv
import re
with open('rtdata.csv', 'rb') as fhand:
reader = csv.reader(fhand)
for row in reader:
url=row[6].strip()
section=re.findall("^http://www.xxxxxxxxx.com/(.*/)", url)
if section==re.findall("^go.*", url):
section=re.findall("^http://www.xxxxxxxxx.com/go/(.*/)", url)
print url
print section
这是一些示例输入输出:
- 示例 1
- 输入:
http://www.xxxxxxxxx.com/go/news/videos/ - 输出:
新闻/视频
- 输入:
- 示例 2
- 输入:
http://www.xxxxxxxxx.com/new-cars/ - 输出:
新车
- 输入:
我在这里缺少什么?
最佳答案
尝试以下操作
s = re.search('http://www.xxxxxxxxx.com/(go/)?(.*)/', url)
section = s.group(2)
而不是
section=re.findall("^http://www.xxxxxxxxx.com/(.*/)", url)
if section==re.findall("^go.*", url):
section=re.findall("^http://www.xxxxxxxxx.com/go/(.*/)", url)
所用正则表达式的直观说明:
http://www.xxxxxxxxx.com/(go/)?(.*)/
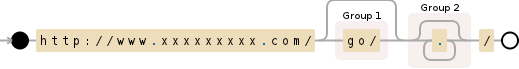
关于python - 简单的Python正则表达式问题,我们在Stack Overflow上找到一个类似的问题: https://stackoverflow.com/questions/19552278/