我有一个从 Windows 事件日志中获取的数据集。 TimeGenerator 列设置为索引。我想要获得一个聚合 View ,按 EventType (info/warn/err) 和索引值显示事件数量。我可以使用 resample() 来设置日期时间分辨率(日期、工作日等)。
这是我的数据框:
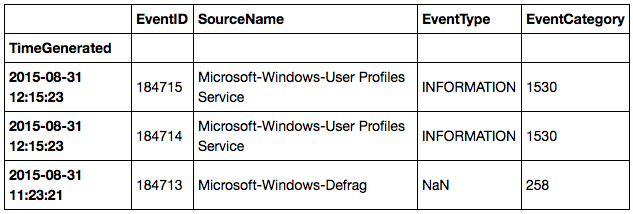
log.info()
<class 'pandas.core.frame.DataFrame'>
DatetimeIndex: 80372 entries, 2015-08-31 12:15:23 to 2015-05-11 04:08:07
Data columns (total 4 columns):
EventID 80372 non-null int64
SourceName 80372 non-null object
EventType 76878 non-null object
EventCategory 80372 non-null int64
dtypes: int64(2), object(2)
memory usage: 3.1+ MB
我当然可以按 EventType 进行分组,但这会降低我的索引:
log[['EventID', 'EventType']].groupby('EventType').count('EventID')
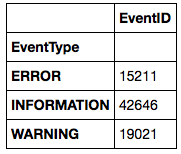
我必须在调用 groupby() 时指定我现有的索引,但如何引用该索引?或者我是否必须在 groupby() 调用之前执行 reset_index() ?或者我只是把这一切都搞错了,而且很明显我是一个 Pandas 新手? ;-)
版本信息:
- Python 3.4.2
- Pandas 0.16.2
- numpy 1.9.2
更新
为了进一步澄清,我想要实现的是:
- EventID 计数(事件数量)
- 按事件类型(在轴 1 中)
- 按时间戳(在轴 0 中)
请注意,时间戳不是唯一的(在原始 DF 中),因为多个事件可能同时发生。
我能够实现我想要的目标的一种方法是:
temp = log.reset_index()
temp.groupby(['TimeGenerated','EventType']).count('EventID'['EventID'].unstack().fillna(0)
在这种情况下,我的输出是:
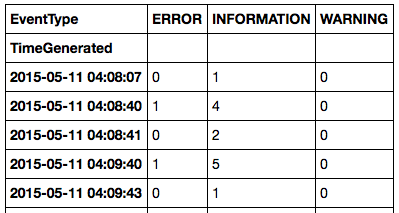
这允许我进一步重新采样计数,例如:
temp.resample('MS', how='sum')
这可行,但我不知道是否必须执行 reset_index() 才能实现此分组。我可以用更好的(阅读:更高效)的方式来完成它吗?
最佳答案
我缺少的是您可以在索引的一个或多个级别上执行groupby()。
test = log.set_index('EventType', append=True)
test = test.groupby(level=[0,1])['EventID'].count('EventID')
test.unstack().fillna(0)
或者,布莱恩·彭德尔顿 (Brian Pendleton) 的建议也有效:
pd.get_dummies(log.EventType)
与最后一种方法的区别在于,如果您需要在列轴中添加另一个级别(例如按主机名),则它效果不佳。但这当然不是最初问题的一部分。
关于python - Pandas DataFrame.groupby 包括索引,我们在Stack Overflow上找到一个类似的问题: https://stackoverflow.com/questions/32415452/