我正在学习CUDA C by Example一书中的 CUDA C 示例(第 5 章中的ripple.cu);当我编译文件时,似乎没有问题;这是我在终端上输入的内容:
nvcc ripple.cu -lGL -lGLU -lX11 -lXi -lXmu -lglut -lGLEW
当我运行可执行文件时,我应该得到这样的图像:

然而,这就是我得到的:
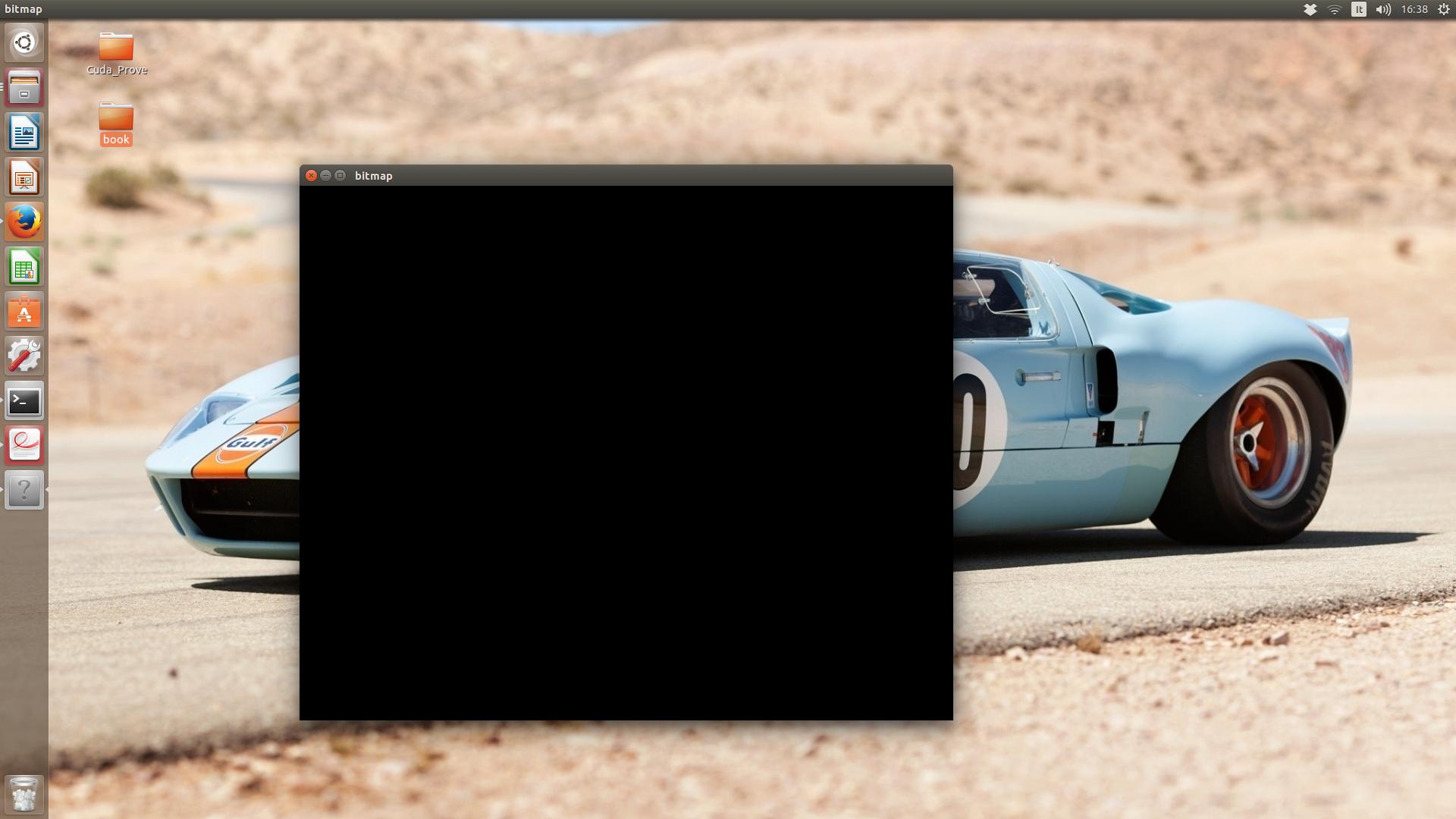
这里我发布文件ripple.cu和相关的头文件:
// ripple.cu
#include "cuda.h"
#include "../common/book.h"
#include "../common/cpu_anim.h"
#define DIM 1024
#define PI 3.1415926535897932f
__global__ void kernel( unsigned char *ptr, int ticks ) {
// map from threadIdx/BlockIdx to pixel position
int x = threadIdx.x + blockIdx.x * blockDim.x;
int y = threadIdx.y + blockIdx.y * blockDim.y;
int offset = x + y * blockDim.x * gridDim.x;
// now calculate the value at that position
float fx = x - DIM/2;
float fy = y - DIM/2;
float d = sqrtf( fx * fx + fy * fy );
unsigned char grey = (unsigned char)(128.0f + 127.0f *
cos(d/10.0f - ticks/7.0f) /
(d/10.0f + 1.0f));
ptr[offset*4 + 0] = grey;
ptr[offset*4 + 1] = grey;
ptr[offset*4 + 2] = grey;
ptr[offset*4 + 3] = 255;
}
struct DataBlock {
unsigned char *dev_bitmap;
CPUAnimBitmap *bitmap;
};
void generate_frame( DataBlock *d, int ticks ) {
dim3 blocks(DIM/16,DIM/16);
dim3 threads(16,16);
kernel<<<blocks,threads>>>( d->dev_bitmap, ticks );
HANDLE_ERROR( cudaMemcpy( d->bitmap->get_ptr(),
d->dev_bitmap,
d->bitmap->image_size(),
cudaMemcpyDeviceToHost ) );
}
// clean up memory allocated on the GPU
void cleanup( DataBlock *d ) {
HANDLE_ERROR( cudaFree( d->dev_bitmap ) );
}
int main( void ) {
DataBlock data;
CPUAnimBitmap bitmap( DIM, DIM, &data );
data.bitmap = &bitmap;
HANDLE_ERROR( cudaMalloc( (void**)&data.dev_bitmap,
bitmap.image_size() ) );
bitmap.anim_and_exit( (void (*)(void*,int))generate_frame,
(void (*)(void*))cleanup );
}
现在我发布包含在名为common的文件夹中的标题:
// book.h
#ifndef __BOOK_H__
#define __BOOK_H__
#include <stdio.h>
static void HandleError( cudaError_t err,
const char *file,
int line ) {
if (err != cudaSuccess) {
printf( "%s in %s at line %d\n", cudaGetErrorString( err ),
file, line );
exit( EXIT_FAILURE );
}
}
#define HANDLE_ERROR( err ) (HandleError( err, __FILE__, __LINE__ ))
#define HANDLE_NULL( a ) {if (a == NULL) { \
printf( "Host memory failed in %s at line %d\n", \
__FILE__, __LINE__ ); \
exit( EXIT_FAILURE );}}
template< typename T >
void swap( T& a, T& b ) {
T t = a;
a = b;
b = t;
}
void* big_random_block( int size ) {
unsigned char *data = (unsigned char*)malloc( size );
HANDLE_NULL( data );
for (int i=0; i<size; i++)
data[i] = rand();
return data;
}
int* big_random_block_int( int size ) {
int *data = (int*)malloc( size * sizeof(int) );
HANDLE_NULL( data );
for (int i=0; i<size; i++)
data[i] = rand();
return data;
}
// a place for common kernels - starts here
__device__ unsigned char value( float n1, float n2, int hue ) {
if (hue > 360) hue -= 360;
else if (hue < 0) hue += 360;
if (hue < 60)
return (unsigned char)(255 * (n1 + (n2-n1)*hue/60));
if (hue < 180)
return (unsigned char)(255 * n2);
if (hue < 240)
return (unsigned char)(255 * (n1 + (n2-n1)*(240-hue)/60));
return (unsigned char)(255 * n1);
}
__global__ void float_to_color( unsigned char *optr,
const float *outSrc ) {
// map from threadIdx/BlockIdx to pixel position
int x = threadIdx.x + blockIdx.x * blockDim.x;
int y = threadIdx.y + blockIdx.y * blockDim.y;
int offset = x + y * blockDim.x * gridDim.x;
float l = outSrc[offset];
float s = 1;
int h = (180 + (int)(360.0f * outSrc[offset])) % 360;
float m1, m2;
if (l <= 0.5f)
m2 = l * (1 + s);
else
m2 = l + s - l * s;
m1 = 2 * l - m2;
optr[offset*4 + 0] = value( m1, m2, h+120 );
optr[offset*4 + 1] = value( m1, m2, h );
optr[offset*4 + 2] = value( m1, m2, h -120 );
optr[offset*4 + 3] = 255;
}
__global__ void float_to_color( uchar4 *optr,
const float *outSrc ) {
// map from threadIdx/BlockIdx to pixel position
int x = threadIdx.x + blockIdx.x * blockDim.x;
int y = threadIdx.y + blockIdx.y * blockDim.y;
int offset = x + y * blockDim.x * gridDim.x;
float l = outSrc[offset];
float s = 1;
int h = (180 + (int)(360.0f * outSrc[offset])) % 360;
float m1, m2;
if (l <= 0.5f)
m2 = l * (1 + s);
else
m2 = l + s - l * s;
m1 = 2 * l - m2;
optr[offset].x = value( m1, m2, h+120 );
optr[offset].y = value( m1, m2, h );
optr[offset].z = value( m1, m2, h -120 );
optr[offset].w = 255;
}
#if _WIN32
//Windows threads.
#include <windows.h>
typedef HANDLE CUTThread;
typedef unsigned (WINAPI *CUT_THREADROUTINE)(void *);
#define CUT_THREADPROC unsigned WINAPI
#define CUT_THREADEND return 0
#else
//POSIX threads.
#include <pthread.h>
typedef pthread_t CUTThread;
typedef void *(*CUT_THREADROUTINE)(void *);
#define CUT_THREADPROC void
#define CUT_THREADEND
#endif
//Create thread.
CUTThread start_thread( CUT_THREADROUTINE, void *data );
//Wait for thread to finish.
void end_thread( CUTThread thread );
//Destroy thread.
void destroy_thread( CUTThread thread );
//Wait for multiple threads.
void wait_for_threads( const CUTThread *threads, int num );
#if _WIN32
//Create thread
CUTThread start_thread(CUT_THREADROUTINE func, void *data){
return CreateThread(NULL, 0, (LPTHREAD_START_ROUTINE)func, data, 0, NULL);
}
//Wait for thread to finish
void end_thread(CUTThread thread){
WaitForSingleObject(thread, INFINITE);
CloseHandle(thread);
}
//Destroy thread
void destroy_thread( CUTThread thread ){
TerminateThread(thread, 0);
CloseHandle(thread);
}
//Wait for multiple threads
void wait_for_threads(const CUTThread * threads, int num){
WaitForMultipleObjects(num, threads, true, INFINITE);
for(int i = 0; i < num; i++)
CloseHandle(threads[i]);
}
#else
//Create thread
CUTThread start_thread(CUT_THREADROUTINE func, void * data){
pthread_t thread;
pthread_create(&thread, NULL, func, data);
return thread;
}
//Wait for thread to finish
void end_thread(CUTThread thread){
pthread_join(thread, NULL);
}
//Destroy thread
void destroy_thread( CUTThread thread ){
pthread_cancel(thread);
}
//Wait for multiple threads
void wait_for_threads(const CUTThread * threads, int num){
for(int i = 0; i < num; i++)
end_thread( threads[i] );
}
#endif
// cpu_anim.h
#endif // __BOOK_H__
这是第二个标题:
// cpu_anim.h
#ifndef __CPU_ANIM_H__
#define __CPU_ANIM_H__
#include "gl_helper.h"
#include <iostream>
struct CPUAnimBitmap {
unsigned char *pixels;
int width, height;
void *dataBlock;
void (*fAnim)(void*,int);
void (*animExit)(void*);
void (*clickDrag)(void*,int,int,int,int);
int dragStartX, dragStartY;
CPUAnimBitmap( int w, int h, void *d = NULL ) {
width = w;
height = h;
pixels = new unsigned char[width * height * 4];
dataBlock = d;
clickDrag = NULL;
}
~CPUAnimBitmap() {
delete [] pixels;
}
unsigned char* get_ptr( void ) const { return pixels; }
long image_size( void ) const { return width * height * 4; }
void click_drag( void (*f)(void*,int,int,int,int)) {
clickDrag = f;
}
void anim_and_exit( void (*f)(void*,int), void(*e)(void*) ) {
CPUAnimBitmap** bitmap = get_bitmap_ptr();
*bitmap = this;
fAnim = f;
animExit = e;
// a bug in the Windows GLUT implementation prevents us from
// passing zero arguments to glutInit()
int c=1;
char* dummy = (char *)(void *)"";
glutInit( &c, &dummy );
glutInitDisplayMode( GLUT_DOUBLE | GLUT_RGBA );
glutInitWindowSize( width, height );
glutCreateWindow( "bitmap" );
glutKeyboardFunc(Key);
glutDisplayFunc(Draw);
if (clickDrag != NULL)
glutMouseFunc( mouse_func );
glutIdleFunc( idle_func );
glutMainLoop();
}
// static method used for glut callbacks
static CPUAnimBitmap** get_bitmap_ptr( void ) {
static CPUAnimBitmap* gBitmap;
return &gBitmap;
}
// static method used for glut callbacks
static void mouse_func( int button, int state,
int mx, int my ) {
if (button == GLUT_LEFT_BUTTON) {
CPUAnimBitmap* bitmap = *(get_bitmap_ptr());
if (state == GLUT_DOWN) {
bitmap->dragStartX = mx;
bitmap->dragStartY = my;
} else if (state == GLUT_UP) {
bitmap->clickDrag( bitmap->dataBlock,
bitmap->dragStartX,
bitmap->dragStartY,
mx, my );
}
}
}
// static method used for glut callbacks
static void idle_func( void ) {
static int ticks = 1;
CPUAnimBitmap* bitmap = *(get_bitmap_ptr());
bitmap->fAnim( bitmap->dataBlock, ticks++ );
glutPostRedisplay();
}
// static method used for glut callbacks
static void Key(unsigned char key, int x, int y) {
switch (key) {
case 27:
CPUAnimBitmap* bitmap = *(get_bitmap_ptr());
bitmap->animExit( bitmap->dataBlock );
//delete bitmap;
exit(0);
}
}
// static method used for glut callbacks
static void Draw( void ) {
CPUAnimBitmap* bitmap = *(get_bitmap_ptr());
glClearColor( 0.0, 0.0, 0.0, 1.0 );
glClear( GL_COLOR_BUFFER_BIT );
glDrawPixels( bitmap->width, bitmap->height, GL_RGBA, GL_UNSIGNED_BYTE, bitmap->pixels );
glutSwapBuffers();
}
};
#endif // __CPU_ANIM_H__
我真的不知道问题可能出在哪里...我已经在 NVIDA 论坛中询问过但没有成功...如果需要,您可以在以下链接中下载源代码:https://developer.nvidia.com/content/cuda-example-introduction-general-purpose-gpu-programming-0
我知道这是一个非常具体的问题,需要花费很多精力来阅读它,但欢迎提出任何建议。
最佳答案
我刚刚弄清楚如何让它工作......所以我基本上将窗口的尺寸从 1024 更改为 512:
ripple.cu:#define DIM 1024 ----> #define DIM 512
我不知道为什么,但现在可以了!我只是运气好而已。
关于c - 无法显示 CUDA C 结果,我们在Stack Overflow上找到一个类似的问题: https://stackoverflow.com/questions/27025993/