我正在尝试一个基本的平均示例,但验证和损失不匹配,并且如果我增加训练时间,网络将无法收敛。我正在训练一个具有 2 个隐藏层的网络,每个隐藏层宽度为 500 个单位,范围为 [0,9] 范围内的三个整数,学习率为 1e-1,Adam,批量大小为 1,丢失 3000 次迭代,并验证每个隐藏层100 次迭代。如果标签和假设之间的绝对差异小于阈值,这里我将阈值设置为1,我认为是正确的。有人可以告诉我这是损失函数选择的问题、Pytorch 的问题还是我正在做的事情吗?下面是一些图:
val_diff = 1
acc_diff = torch.FloatTensor([val_diff]).expand(self.batch_size)
验证期间循环 100 次:
num_correct += torch.sum(torch.abs(val_h - val_y) < acc_diff)
在每个验证阶段后附加:
validate.append(num_correct / total_val)
以下是(假设和标签)的一些示例:
[...(-0.7043088674545288, 6.0), (-0.15691305696964264, 2.6666667461395264),
(0.2827358841896057, 3.3333332538604736)]
我尝试了 API 中通常用于回归的六个损失函数:
torch.nn.L1Loss(size_average=False)
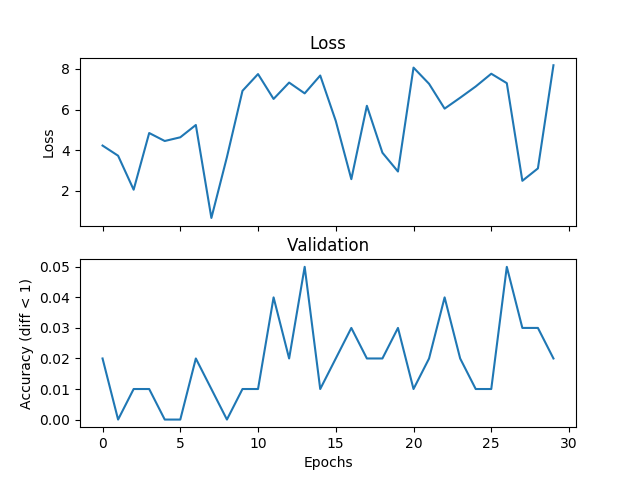
torch.nn.L1Loss()
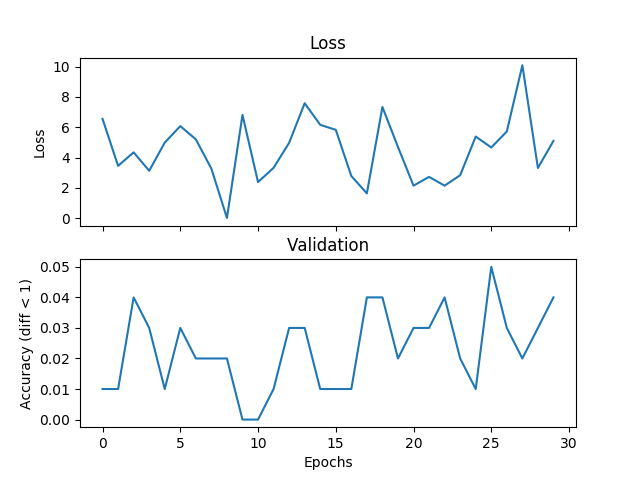
torch.nn.MSELoss(size_average=False)
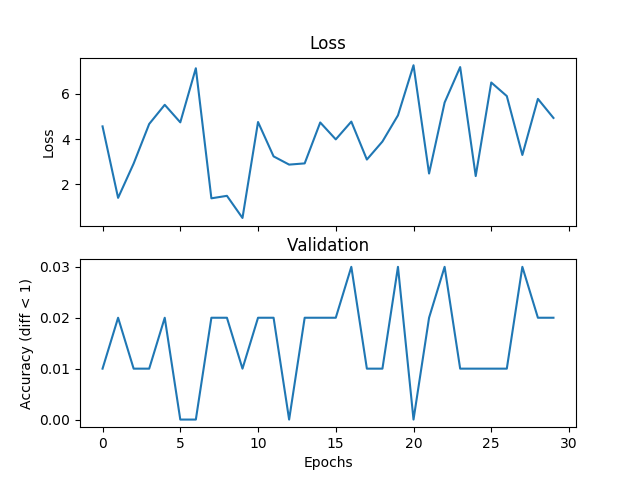
torch.nn.MSELoss()

torch.nn.SmoothL1Loss(size_average=False)
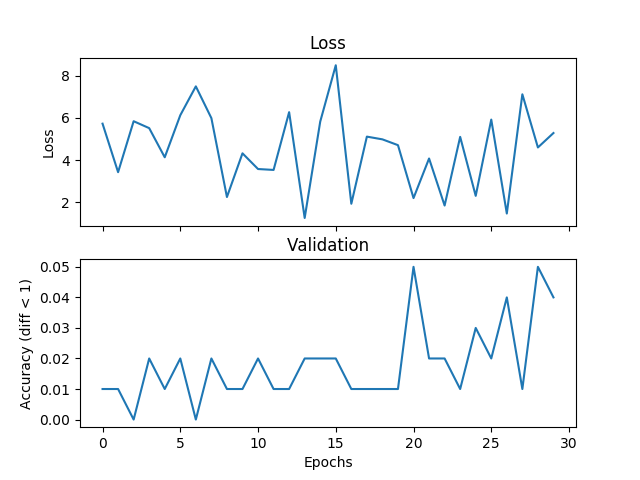
torch.nn.SmoothL1Loss()

谢谢。
网络代码:
class Feedforward(nn.Module):
def __init__(self, topology):
super(Feedforward, self).__init__()
self.input_dim = topology['features']
self.num_hidden = topology['hidden_layers']
self.hidden_dim = topology['hidden_dim']
self.output_dim = topology['output_dim']
self.input_layer = nn.Linear(self.input_dim, self.hidden_dim)
self.hidden_layer = nn.Linear(self.hidden_dim, self.hidden_dim)
self.output_layer = nn.Linear(self.hidden_dim, self.output_dim)
self.dropout_layer = nn.Dropout(p=0.2)
def forward(self, x):
batch_size = x.size()[0]
feat_size = x.size()[1]
input_size = batch_size * feat_size
self.input_layer = nn.Linear(input_size, self.hidden_dim).cuda()
hidden = self.input_layer(x.view(1, input_size)).clamp(min=0)
for _ in range(self.num_hidden):
hidden = self.dropout_layer(F.relu(self.hidden_layer(hidden)))
output_size = batch_size * self.output_dim
self.output_layer = nn.Linear(self.hidden_dim, output_size).cuda()
return self.output_layer(hidden).view(output_size)
训练代码:
def train(self):
if self.cuda:
self.network.cuda()
dh = DataHandler(self.data)
# loss_fn = nn.L1Loss(size_average=False)
# loss_fn = nn.L1Loss()
# loss_fn = nn.SmoothL1Loss(size_average=False)
# loss_fn = nn.SmoothL1Loss()
# loss_fn = nn.MSELoss(size_average=False)
loss_fn = torch.nn.MSELoss()
losses = []
validate = []
hypos = []
labels = []
val_size = 100
val_diff = 1
total_val = float(val_size * self.batch_size)
for i in range(self.iterations):
x, y = dh.get_batch(self.batch_size)
x = self.tensor_to_Variable(x)
y = self.tensor_to_Variable(y)
self.optimizer.zero_grad()
loss = loss_fn(self.network(x), y)
loss.backward()
self.optimizer.step()
最佳答案
看来您误解了 pytorch 中图层的工作原理,这里有一些提示:
当您这样做时,在您的转发中
nn.Linear(...)您正在定义新层,而不是使用您在网络中预定义的层__init__。因此,它无法学习任何东西,因为权重不断重新初始化。您不需要调用
.cuda()里面net.forward(...)因为您已经在train中复制了 GPU 上的网络通过调用self.network.cuda()理想情况下是
net.forward(...)输入应该直接具有第一层的形状,因此您不必修改它。在这里你应该有x.size() <=> Linear -- > (Batch_size, Features).
您的转发应该与此接近:
def forward(self, x):
x = F.relu(self.input_layer(x))
x = F.dropout(F.relu(self.hidden_layer(x)),training=self.training)
x = self.output_layer(x)
return x
关于python - 回归损失函数不正确,我们在Stack Overflow上找到一个类似的问题: https://stackoverflow.com/questions/45490265/