我是 Keras(使用 TensorFlow 后端)的新手,正在使用它对用户评论进行一些简单的情感分析。由于某种原因,我的循环神经网络产生了一些我不理解的异常结果。
首先,我的数据是来自 UCI ML archive 的直接情感分析训练和测试集。 。训练实例有 2061 个,规模较小。数据如下所示:
text label
0 So there is no way for me to plug it in here i... 0
1 Good case, Excellent value. 1
2 Great for the jawbone. 1
3 Tied to charger for conversations lasting more... 0
4 The mic is great. 1
第二,这是一个产生良好结果的 FFNN 实现。
# FFNN model.
# Build the model.
model_ffnn = Sequential()
model_ffnn.add(layers.Embedding(input_dim=V, output_dim=32))
model_ffnn.add(layers.GlobalMaxPool1D())
model_ffnn.add(layers.Dense(10, activation='relu'))
model_ffnn.add(layers.Dense(1, activation='sigmoid'))
model_ffnn.summary()
# Compile and train.
model_ffnn.compile(optimizer='rmsprop', loss='binary_crossentropy', metrics=['acc'])
EPOCHS = 50
history_ffnn = model_ffnn.fit(x_train, y_train, epochs=EPOCHS,
batch_size=128, validation_split=0.2, verbose=3)
正如您所看到的,随着轮数的增加,学习曲线会产生平滑的改进。
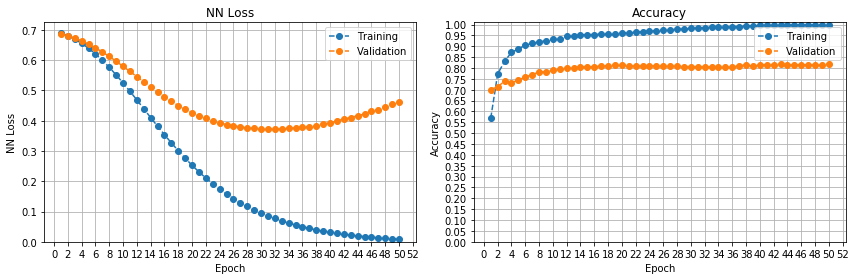
第三,问题就在这里。我使用 GRU 训练了一个循环神经网络,如下所示。我还尝试了 LSTM 并看到了相同的结果。
# GRU model.
# Build the model.
model_gru = Sequential()
model_gru.add(layers.Embedding(input_dim=V, output_dim=32))
model_gru.add(layers.GRU(units=32))
model_gru.add(layers.Dense(units=1, activation='sigmoid'))
model_gru.summary()
# Compile and train.
model_gru.compile(optimizer='rmsprop', loss='binary_crossentropy', metrics=['acc'])
EPOCHS = 50
history_gru = model_gru.fit(x_train, y_train, epochs=EPOCHS,
batch_size=128, validation_split=0.2, verbose=3)
然而,学习曲线却很不寻常。您可以看到一个平台期,直到第 17 轮左右,损失和准确率都没有提高,然后模型开始学习和改进。我以前从未在训练开始时遇到过这种平台期。
任何人都可以解释为什么会出现这种停滞状态,为什么它会停止并让位于逐步学习,以及我如何避免它?
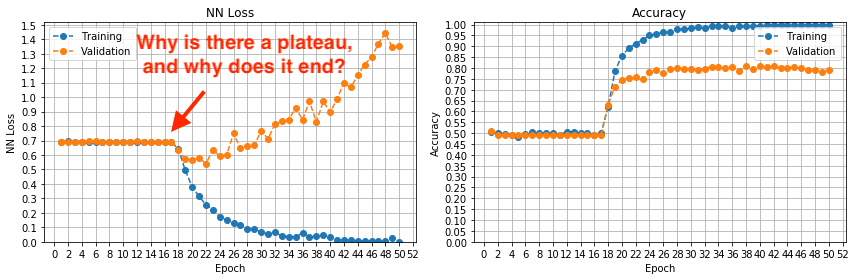
最佳答案
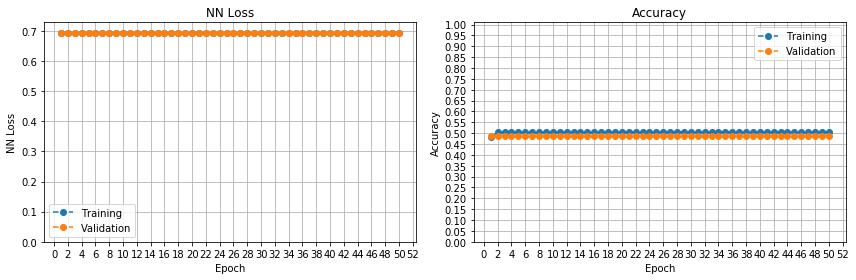
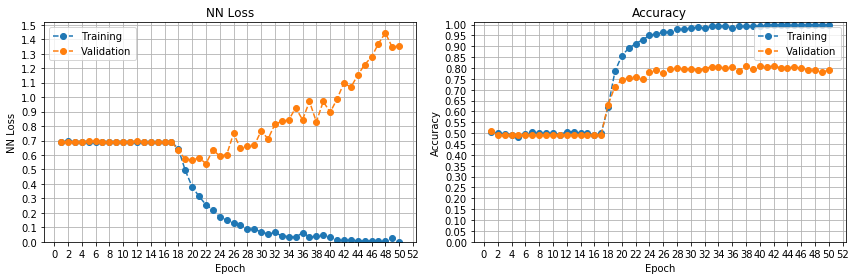
根据@Gerges Dib 的评论,我按升序尝试了不同的学习率。
lr = 0.0001
lr = 0.001(RMSprop 的默认学习率)
lr = 0.01

lr = 0.05
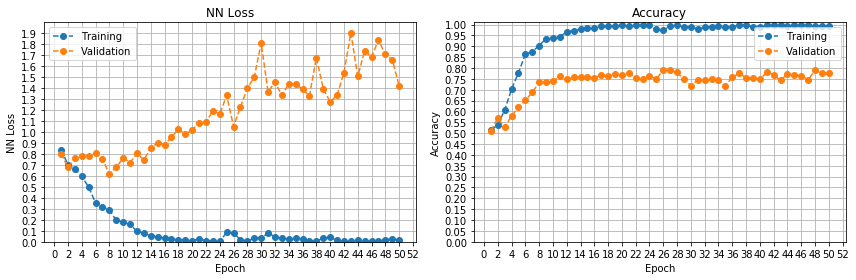
lr = 0.1
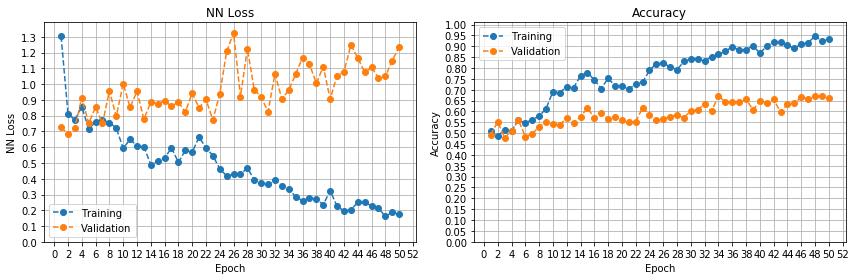
这很有趣。看来平台期是由于优化器的学习率太低造成的。参数一直停留在局部最优状态,直到出现突破。我以前从未见过这种模式。
关于python - Keras RNN(GRU、LSTM)产生平稳期然后改进,我们在Stack Overflow上找到一个类似的问题: https://stackoverflow.com/questions/54118546/