我的问题与强化学习的实现无关,而是当每个状态都是终止状态时理解强化学习的概念。
我举个例子:一个机器人正在学习踢足球,只是学习射门。奖励是球射门后与球门柱之间的距离。状态是多个特征的数组, Action 是三维力的数组。
如果我们考虑情景强化学习,我觉得这种方法没有意义。事实上,机器人射击并给予奖励:每一集都是最后一集。将下一个状态传递给系统是没有意义的,因为算法不关心它来优化奖励 - 在这种情况下,我将使用 Actor-Critic 方法来处理连续状态和 Action 空间。有人可能会认为不同的监督学习方法(例如深度神经网络)可能效果更好。但我不确定,因为在这种情况下,算法将无法在输入远离训练集的情况下取得良好的结果。据我所知,强化学习能够更好地概括这种情况。
问题是:强化学习是解决这个问题的有效方法吗?在这种情况下如何管理终端状态?您知道文献中类似的例子吗?
最佳答案
如果我正确理解了您的问题,那么您所描述的问题在文献中被称为Contextual Bandits。在这种情况下,您有一组状态,并且代理在执行一个操作后会收到奖励。这个问题与强化学习密切相关,但它们有一些特殊的特征,可以用来设计特定的算法。
下图,摘自Arthur Juliani's post ,显示了多臂老虎机、上下文老虎机和强化学习问题之间的主要区别:
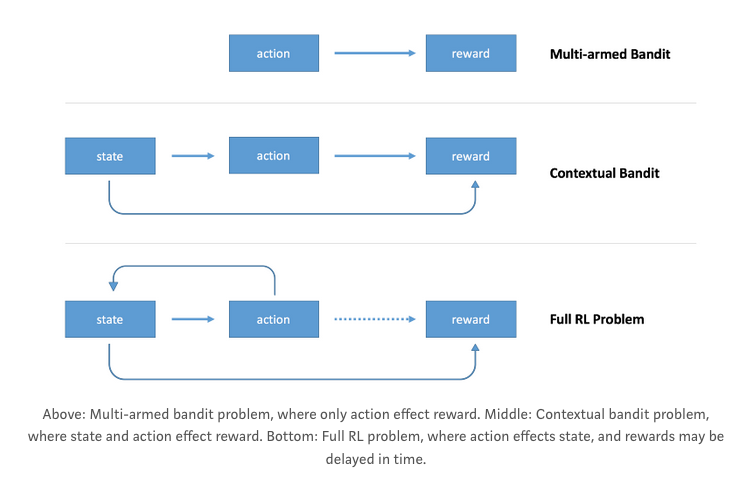
关于machine-learning - 每个状态都是终端的强化学习,我们在Stack Overflow上找到一个类似的问题: https://stackoverflow.com/questions/54870581/