我是 Spark 新手,我想制作一个流媒体程序。我需要预测每一行的重复次数。这是我的原始数据:
05:49:56.604899 00:00:00:00:00:02 > 00:00:00:00:00:03, ethertype IPv4 (0x0800), length 10202: 10.0.0.2.54880 > 10.0.0.3.5001: Flags [.], seq 3641977583:3641987719, ack 129899328, win 58, options [nop,nop,TS val 432623 ecr 432619], length 10136
05:49:56.604908 00:00:00:00:00:03 > 00:00:00:00:00:02, ethertype IPv4 (0x0800), length 66: 10.0.0.3.5001 > 10.0.0.2.54880: Flags [.], ack 10136, win 153, options [nop,nop,TS val 432623 ecr 432623], length 0
05:49:56.604900 00:00:00:00:00:02 > 00:00:00:00:00:03, ethertype IPv4 (0x0800), length 4410: 10.0.0.2.54880 > 10.0.0.3.5001: Flags [P.], seq 10136:14480, ack 1, win 58, options [nop,nop,TS val 432623 ecr 432619], length 4344
我编写了一个代码来提取合适的输出,如下所示。 (我需要列 1 和列 2 上的重复次数)
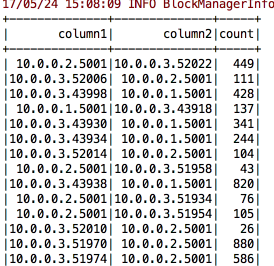
这是我的代码:
但是我的代码不处于流模式。我做了另一个代码来获得流模式。因为train.csv文件是以流式方式生成的。但我遇到了一些错误。 这是我的流代码:
import org.apache.spark.SparkConf
import org.apache.spark.mllib.linalg.Vectors
import org.apache.spark.mllib.regression.{LabeledPoint, StreamingLinearRegressionWithSGD}
import org.apache.spark.sql.Row
import org.apache.spark.sql.types.{StringType, StructField, StructType}
import org.apache.spark.streaming.{Seconds, StreamingContext}
import scala.util.Try
/**
* Created by saeedtkh on 5/24/17.
*/
object Main_ML_with_Streaming {
def main(args: Array[String]) {
val conf = new SparkConf().setAppName("saeed_test").setMaster("local[*]")
//val sc = new SparkContext(conf)
val ssc = new StreamingContext(conf, Seconds(5))
/////////////////////Start extract the packet
val customSchema = StructType(Array(
StructField("column0", StringType, true),
StructField("column1", StringType, true),
StructField("column2", StringType, true)))
val rdd = ssc.textFileStream("/Users/saeedtkh/Desktop/sharedsaeed/train.csv")
val rowRdd =rdd.map(line => line.split(">")).map(array => {
val first = Try(array(0).trim.split(" ")(0)) getOrElse ""
val second = Try(array(1).trim.split(" ")(6)) getOrElse ""
val third = Try(array(2).trim.split(" ")(0).replace(":", "")) getOrElse ""
Row.fromSeq(Seq(first, second, third))
})
val dataFrame_trainingData = sqlContext.createDataFrame(rowRdd, customSchema)
dataFrame_trainingData.groupBy("column1","column2").count().show()
/////////////////////end extract the packet
val testData = ssc.textFileStream(/Users/saeedtkh/Desktop/sharedsaeed/test.csv).map(LabeledPoint.parse)
////////////////////end trainging and testing
val numFeatures = 3
val model = new StreamingLinearRegressionWithSGD()
.setInitialWeights(Vectors.zeros(numFeatures))
model.trainOn(dataFrame_trainingData)
model.predictOnValues(testData.map(lp => (lp.label, lp.features))).print()
ssc.start()
ssc.awaitTermination()
print("Here is the anwser: *****########*********#########*******222")
}
}
问题是,我无法在代码中的这一行中使用 sqlcontext 创建数据框:
val dataFrame_trainingData = sqlContext.createDataFrame(rowRdd, customSchema)
任何人都可以帮助我修改这段以流方式工作的代码,并使用线性回归或任何其他算法预测每行的重复。多谢。
更新1:
根据第一个答案,我添加了 foreach 但错误仍然存在:
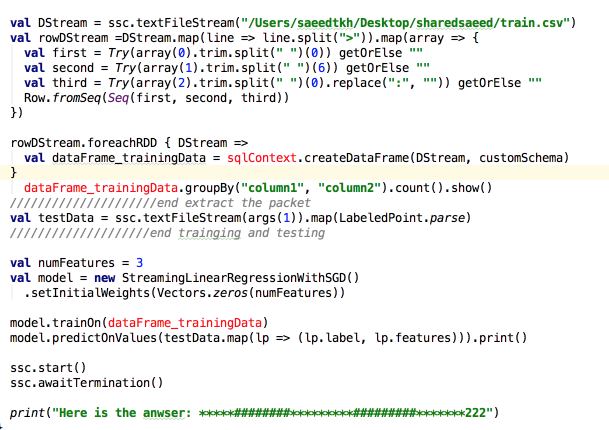
最佳答案
首先,需要注意的是 ssc.textFileStream 返回 DStream而不是 RDD,因此您命名为 rdd、rowRdd 和 testData 的变量并不是真正的 RDD,而是对连续 RDD 序列的抽象。因此,您无法将这些传递给需要 RDD 的 createDataFrame。
您可以使用DStream.foreachRDD从每个底层RDD中创建一个DataFrame,如here所述。 :
rowRdd.foreachRDD { rdd =>
val dataFrame_trainingData = sqlContext.createDataFrame(rdd, customSchema)
// ...
}
但是,您应该注意到 StreamingLinearRegressionWithSGD期望 DStreams 作为 trainOn 和 predictOnValues 的输入 - 因此您可以简单地传递原始 DStreams,而不用将它们转换为 DataFrames。
关于scala - 我无法使用流模式在 apache Spark 中使用 scala 进行在线预测来制作数据帧,我们在Stack Overflow上找到一个类似的问题: https://stackoverflow.com/questions/44159607/