编辑: 我正在尝试通过 r 中的 kNN(插入符号包)分类器对数据集进行建模,但它运行了很长时间。最终我停止了它。有时我会停止它,它说“使用警告()查看所有警告消息”。当我这样做时,它会显示数据集中的每一列都有“很多联系”。我在这里找到了解决这个问题的一些解决方案,但没有一个适合我的情况。他们说“将一些伪随机噪声数据放入数据集中,它就会起作用”。我试过了,没用:
https://stats.stackexchange.com/questions/25926/dealing-with-lots-of-ties-in-knn-model
结束编辑。
这就是为什么我将我的训练数据集的链接提供给你们,所以也许你们中的一个人可以理解为什么 kNN 在建模时卡住:
http://www.htmldersleri.org/train.csv (这是众所周知的Reuters-21578数据集)
这是 kNN r 行:
knn<-train(as.factor(class)~.,data=as.matrix(train),method="kNN")
或
knn<-train(as.factor(class)~.,data=train,method="kNN")
它们都不起作用。
顺便说一句,使用 svmLinear 代替 kNN 也不起作用。
还有一个重要提示:我在所有列上应用了 unique() 函数,我注意到没有任何列只有一个值。它们都是不同的。
最后,这是我的项目报告中的数据集信息部分,可能有用:
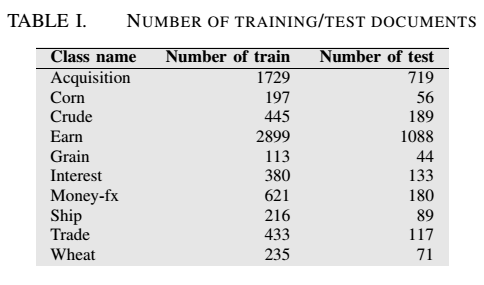
In Reuters-21578 dataset, we used top ten classes; 7269 samples in training set and 2686 samples in test set. The distribution of the classes is unbalanced. The maximum class has 2899 documents, occupying 39,88% of training set. The minimum class has 113 documents, occupying 1,55% of training set. Table I shows the ten most frequent categories along with the number of training and test set examples in each.
最佳答案
为什么 kNN 和 SVM 在此数据集上运行缓慢
k-最近邻 (kNN) 和支持向量机(SVM,您稍后在问题中提到)的复杂性随着样本大小 (n )增加。概括地说,您可以将其视为 Big O notation 中的二次 O(n^2) 增长率。 ,尽管事实比这更加微妙。
对于 kNN,原因很容易理解:它需要构建一个 train-n x test-n 距离矩阵。这意味着,在包含 1,415 个示例的数据集上执行 kNN 或 SVM 的时间可能是在包含 1,000 个示例的数据集上执行相同操作所需的两倍,因为时间是训练的函数 - n x 测试-n。
因此,这些算法可以在内存中处理的数据集大小存在上限,这比逻辑回归或梯度增强机等的限制要低得多。
提高速度
将数据分组将为您带来二次方的性能提升。例如,将 n=2000 数据集随机拆分为 2 个 n=1000 数据集,性能将提高 4 倍。
处理关系
但更重要的是,您似乎正在尝试根据 calcategories 输入数据训练模型。 kNN 设计用于处理数字输入数据。分类变量必须是 recoded as dummy variables 。您不会收到错误消息,因为分类变量存储为数字代码,但这并不意味着这些数字对于 kNN 的距离计算具有数学意义。
您获得了很多联系,因为您的数据集包含许多编码为整数的分类变量,而可能的值相对较少。您可以通过以下几种方式处理这个问题:
对分类变量运行对应分析,然后对对应分析返回的值(连续且正交的)运行 kNN。
FactoMineR库有一个记录完善的函数MCA,用于多重对应分析。将每个因子转换为虚拟变量(如上面的链接中所述),然后使用更适合稀疏数据的距离度量 - cosine similarity 。不幸的是,您无法从
caret运行具有余弦相似度的 kNN,但可以手动实现,如 this SO thread 中所述。 .
关于r - kNN - r 中有很多关系,我们在Stack Overflow上找到一个类似的问题: https://stackoverflow.com/questions/37073062/