我有一百万个样本,大约有1000个功能。但是,每个样本仅测量特征的子集。我想进行机器学习以根据功能预测结果,但是,我不知道如何处理丢失的数据。由于数据是按随机顺序丢失的,因此我无法根据丢失的功能对数据进行分类,因为类的数量很大,每个类中的样本很少。解决此类问题的最佳解决方案是什么?
最佳答案
处理缺失值的方法
1.删除:
它有两种类型:明智删除列表和明智删除对。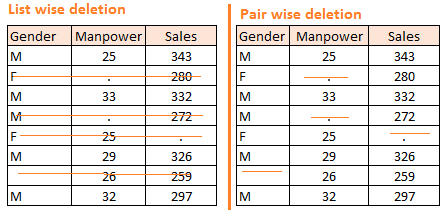
在列表明智删除中,我们删除任何
变量丢失。简单性是此功能的主要优势之一
方法,但是此方法降低了模型的功效,因为它降低了
样本量。
在成对删除中,我们对所有以下情况进行分析:
存在感兴趣的变量。这种方法的优点是
它可以保留尽可能多的案例以供分析。其中一个
这种方法的缺点,它使用不同的样本量
不同的变量。
当丢失的数据的性质是“缺少”时,使用删除方法
完全随机”,否则非随机缺失值可能会使
模型输出。
2.均值/众数/中位数插补:
插补是一种用估计值填充缺失值的方法。目的是采用可以在数据集的有效值中标识的已知关系,以帮助估计缺失值。均值/众数/中位数插补是最常用的方法之一。它包括用该变量所有已知值的均值或中位数(定量属性)或众数(定性属性)替换给定属性的缺失数据。它可以有两种类型:
广义归因:在这种情况下,我们计算平均值或中位数
对于该变量的所有非缺失值,然后替换缺失
均值或中位数的值。像上表一样,变量“ Manpower”
缺失,因此我们取所有“人力”的所有不缺失值的平均值
(28.33),然后用它替换缺失值。
相似情况的估算:在这种情况下,我们计算
性别“男”(29.75)和“女”(25)各自不丢失
然后根据性别替换缺失值。对于“男性”,我们
将用29.75和“女性”替换缺少的人力值
25岁
3.预测模型:
预测模型是用于处理丢失数据的复杂方法之一。在这里,我们创建了一个预测模型来估计将替代缺失数据的值。在这种情况下,我们将数据集分为两组:一组没有变量的缺失值,另一组没有值。第一个数据集成为模型的训练数据集,而具有缺失值的第二个数据集是测试数据集,具有缺失值的变量被视为目标变量。接下来,我们基于训练数据集的其他属性创建一个模型来预测目标变量并填充测试数据集的缺失值,我们可以使用回归,ANOVA,Logistic回归和各种建模技术来执行此操作。这种方法有两个缺点:
模型估计值通常比
真实价值
如果数据集中的属性与
属性缺少值,则该模型将不适合
估计缺失值。
4. KNN归因:
在这种估算方法中,使用给定数量的属性来估算属性的缺失值,这些给定数量的属性最类似于其值缺失的属性。使用距离函数确定两个属性的相似性。还已知具有某些优点和缺点。
优点:
k近邻可以预测定性和定量
属性
为缺少数据的每个属性创建预测模型
不需要
具有多个缺失值的属性可以轻松处理
考虑到数据的相关结构
坏处:
在分析大型数据库时,KNN算法非常耗时。它
搜索所有数据集以查找最相似的数据
实例。
k值的选择非常关键。 k的较高值包括
与我们需要的属性明显不同的属性
而较低的k值表示缺少显着性
属性。
资料来源:https://www.analyticsvidhya.com/blog/2016/01/guide-data-exploration/
关于machine-learning - 数据不完整的机器学习,我们在Stack Overflow上找到一个类似的问题: https://stackoverflow.com/questions/39386936/