我使用 sci-kit learn 构建了一个随机森林模型来预测保险续保。这很棘手,因为在我的数据集中,96.24% 的人会续订,而只有 3.76% 的人不续订。运行模型后,我使用混淆矩阵、分类报告和 ROC 曲线评估模型性能。
[[ 2448 8439]
[ 3 278953]]
precision recall f1-score support
0 1.00 0.22 0.37 10887
1 0.97 1.00 0.99 278956
avg / total 0.97 0.97 0.96 289843
我的 ROC 曲线如下所示:
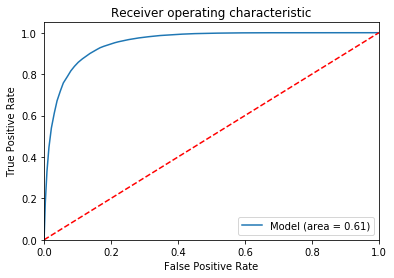
该模型预测续订率略低于 100%(四舍五入至 1.00,请参阅召回栏),不续订率约为 22%(请参阅召回栏)。 ROC 曲线表明曲线下的面积远大于图右下部分所示的面积(面积 = 0.61)。
有人知道为什么会发生这种情况吗?
谢谢!
最佳答案
在类别高度不平衡的情况下,ROC 被证明是一个不合适的指标。更好的衡量标准是使用平均精度或 PR 曲线下的面积。
此支持Kaggle link在类似的问题设置中讨论完全相同的问题。
This answer and the linked paper解释 PR 曲线下最佳面积的优化也将给出最佳 ROC。
关于machine-learning - 混淆矩阵和ROC曲线,我们在Stack Overflow上找到一个类似的问题: https://stackoverflow.com/questions/51405567/