我希望编写一种方法来解析包含人名及其年龄的字符串。例如:
Manuel 8
Mustafa 16
Zhihao 12
Itsuki 12
Louis 11
Farah 11
即字符串的规范为%N %A,其中%N代表姓名,%A代表年龄。
但是,字符串的规范并不固定(例如,在另一个文档中可能是 %Nage:%A 或 %N (%A)),因此解析方法应该能够将规范作为其参数之一。
换句话说,解析方法应该像这样工作:
Data d1 = Parser.parse("Indira 15", "%N %A");
Data d2 = Parser.parse("12 Shu-chen", "%A %N");
Data d3 = Parser.parse("Hana (12)", "%N (%A)");
Data d4 = Parser.parse("Name: Sophia [12]", "Name: %N [%A]");
其中Data和Parser定义如下:
public class Data {
private String name;
private int age;
public Data(String name, int age) {
this.name = name;
this.age = age;
}
// + getter and setter methods.
}
public class Parser {
public static Data parse(String s, String specification) {
// --- What to do here? ---
return (new Data(name, age));
}
}
如何编写Parser.parse?换句话说,如何使用字符串规范来解析字符串?
最佳答案
在这里,我们可以有一个表达式并将我们想要的输出分为两组,例如:
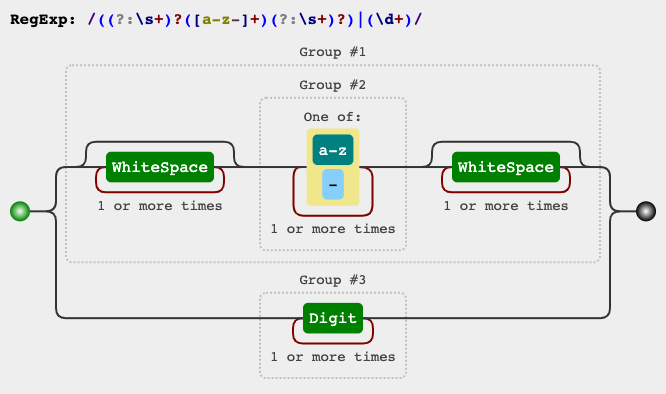
((?:\s+)?([a-z-]+)(?:\s+)?)|(\d+)
我们想要的名字在这个([a-z-]+)组中,年龄信息在这个(\d+)中,其余的可以简单地写脚本化的。
测试
import java.util.regex.Matcher;
import java.util.regex.Pattern;
final String regex = "((?:\\s+)?([a-z-]+)(?:\\s+)?)|(\\d+)";
final String string = "Indira 15\n"
+ "12 Shu-chen\n"
+ "Hana (12)\n"
+ "Sophia [12]\n"
+ " Manuel 8\n"
+ "Mustafa 16\n"
+ "Zhihao 12\n"
+ "Itsuki 12\n"
+ "Louis 11\n"
+ "Farah 11";
final Pattern pattern = Pattern.compile(regex, Pattern.MULTILINE | Pattern.CASE_INSENSITIVE);
final Matcher matcher = pattern.matcher(string);
while (matcher.find()) {
System.out.println("Full match: " + matcher.group(0));
for (int i = 1; i <= matcher.groupCount(); i++) {
System.out.println("Group " + i + ": " + matcher.group(i));
}
}
DEMO
正则表达式电路
jex.im可视化正则表达式:
DEMO 2
建议
基于zdim的建议:
(1) I think that (?:\s+)? (at least one space, but the whole thing is optional) is the same as \s* (optional spaces)
(2) In the second group of spaces I think that you want to require at least a space, so just \s+.
我们可以大大简化和修改我们的初始表达式,使其类似于:
(\s*([a-z-]+)\s+)|(\d+)
DEMO
关于java - 如何使用字符串规范解析字符串?,我们在Stack Overflow上找到一个类似的问题: https://stackoverflow.com/questions/56014624/