我有一个大约有 220 万行的表,在该表上我试图通过一些连接来提取查询。这些连接之一是子查询。我已经对其进行了尽可能多的优化,但没有完全重写应用程序代码。
以下是此特定查询的 EXPLAIN() 的结果:

正如我用红色突出显示的那样,点击表中有很多记录需要浏览。第 4 行是我的子查询连接,但运行我自己的测试时,缓慢似乎来自于那个巨大的表。
因此,当我运行此查询时,我正在查看 Amazon CloudWatch 中预置的 IOPS 和延迟:
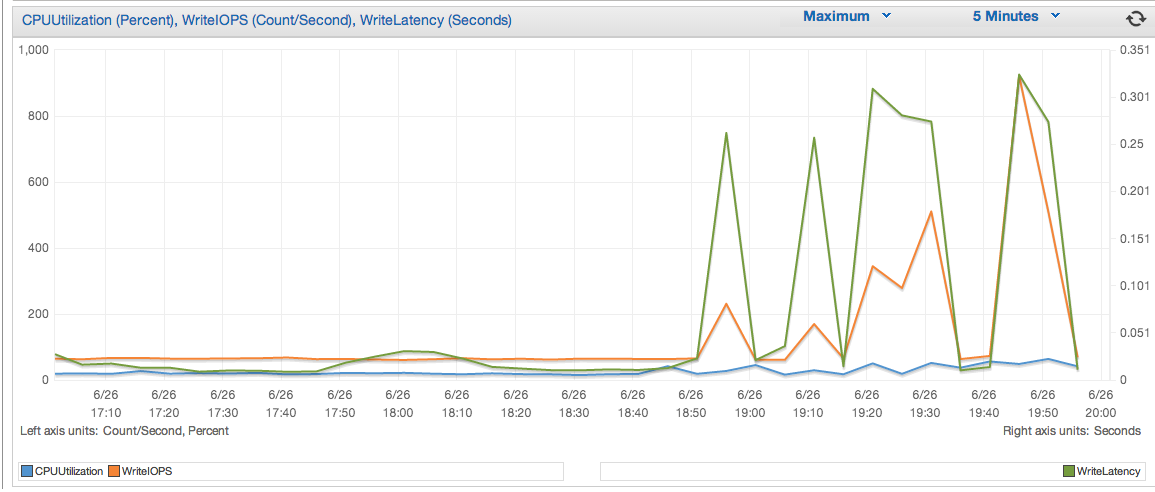
由此可见,我需要更多预配置 IOPS 是否公平?我现在只有1000。
我真的知道在这里还能做什么。
我还想知道 - 我在此 RDS 上有一个只读副本,在队列中的只读副本上运行此查询是否有意义,以便我的主数据库不会影响生产性能?
最佳答案
我决定创建一个只读副本并将所有这些冗长的查询卸载到那里。
这些查询大多数用于客户报告,当客户在数据库中进行大量点击时,页面会运行很长时间并最终超时。因此,使用此只读副本,我使用 cron 作业创建了一个报告队列系统。我不会即时向他们提供报告,而是将其排队并在只读副本准备就绪后通过电子邮件发送给他们。问题解决了!我希望。
关于php - 使用 Amazon RDS 查询大型 MySQL 表,我们在Stack Overflow上找到一个类似的问题: https://stackoverflow.com/questions/24439494/