我有两个 CSV,理想情况下这些 CSV 将包含相同的数据,但实际上有时内容可能会有所不同。我不是手动浏览两个 CSV 并找出相同和不同的内容,而是尝试创建一个 Python 脚本,每周运行该脚本来告诉我什么相同、什么不同。
逻辑是这样的。 1. 给定 2 个 CSV 2. 逐行比较它们。 3. 两个 CSV 之间的任何不同行都应记录到另一个 CSV 中(整行) 4. CSV 之间任何相同的行都应记录到另一个 CSV 中(整行)。
这将帮助我直观地了解差异并采取相应的行动。
下面是我正在寻找的示例。
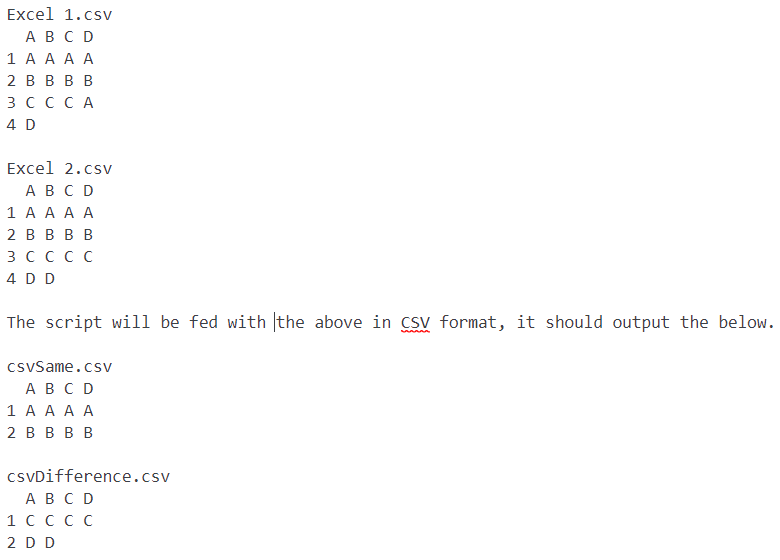
下面的代码是我到目前为止所拥有的
with open('Excel 1.csv', 'r') as csvOne, open('Excel 2.csv', 'r') as csvTwo:
csvOne = csvOne.readlines()
csvTWO = csvTWO.readlines()
with open('resultsSame.csv', 'w') as resultFileSame:
for row in csvTWO:
if row not in csvONE:
resultFileSame.write(row)
with open('resultsDifference.csv', 'w') as resultFileDifference:
for row in csvTWO:
if row in csvONE:
resultFileDifference.write(row)
我希望脚本比较行,并且仅当行之间存在相似性或差异时才输出到另一组 CSV 中。上面的代码有效,但它删除了一个 CSV 中的列,而不是其他 CSV 中的列,也不是行。我想保留这些列,即使它们不在另一个 CSV 中,并且只向我显示单独的 CSV 中的一个或另一个中的角色。
请在下面查看我在数据集示例中运行您提供的第一个代码时得到的结果。


如果你看看上面的内容,我似乎不太明白你是如何得到你的输出的,因为这正是我想要的!老实说,我不需要打印出标题,因为我也在比较这些标题,有时由于用户错误,它们可能会结束不同的标题。

最佳答案
这是您的代码的修改版本。
with open('excel1.csv', 'r') as csvOne, open('excel2.csv', 'r') as csvTwo:
csvONE = csvOne.readlines()
csvTWO = csvTwo.readlines()
with open('resultsDifference.csv', 'w') as resultFileDifference:
# Write the header to difference file.
# Because, the headers are same for 2 input CSVs, the header row will be obviously into resultsSame.csv
resultFileDifference.write(csvONE[0])
for row in csvTWO:
if row not in csvONE:
resultFileDifference.write(row)
with open('resultsSame.csv', 'w') as resultFileSame:
for row in csvTWO:
if row in csvONE:
resultFileSame.write(row)
关于python - 在Python 3中创建一个脚本来比较两个CSV并将两者之间的异同输出到另一组CSV中,我们在Stack Overflow上找到一个类似的问题: https://stackoverflow.com/questions/47474986/