我使用了 MariaDB 服务器,并尝试连接并将数据放入 python 中的 pandas 数据帧中。
MariaDB 如下所示:
CREATE DATABASE `fhem` DEFAULT CHARACTER SET utf8 COLLATE utf8_bin;
包含表当前和历史。
CREATE TABLE `fhem`.`history` (TIMESTAMP TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP, DEVICE varchar(64), TYPE varchar(64), EVENT varchar(512), READING varchar(64), VALUE varchar(128), UNIT varchar(32));
我可以在python中成功连接:
import pandas as pd
import sqlalchemy as db
engine = db.create_engine('mysql+mysqlconnector://user:pass@192.168.37.33:3306/fhem')
data = pd.read_sql_table('history', engine)
数据框具有正确的标题:
['TIMESTAMP', 'DEVICE', 'TYPE', 'EVENT', 'READING', 'VALUE', 'UNIT']
但是单元格的格式不正确。它们看起来像
[50, 50, 46, 51]
应该是这样的
"on" or "off"
如果我在终端中使用 mysql -u user .. SELCET * from History; 进行查询,我会得到正确的数据。 我尝试添加
engine = db.create_engine('mysql+mysqlconnector://user:pass@192.168.37.33:3306/fhem', encoding='utf8')
engine = db.create_engine('mysql+mysqlconnector://user:pass@192.168.37.33:3306/fhem?charset=utf8')
但这也没有帮助。唯一正确显示的列是TIMESTAMP。
我能做的是:
for l in data['VALUE'].values:
x = l.decode('utf-8')
print(x)
我可以对我感兴趣的每一列执行此操作,而不是将其添加到新的 df 中,但我想必须有更好的方法。你能帮我吗?
编辑
我有以下选择:
print(data['VALUE'])
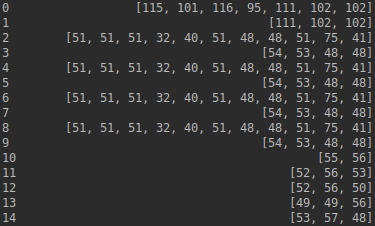
for l in data['VALUE']:
print(l)

for l in data['VALUE']:
print(l.decode('utf-8'))
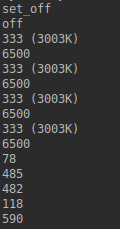
最后一个,就是我瞄准的df。 我试过了
data['VALUE'].apply(lambda x: x.decode('utf-8'))
什么也不做。 我在 pandas 0.23.4 和 sqlalchemy 1.2.12 上运行
法比安
最佳答案
我的系统在 VM Ubuntu 18.04 LTS 上运行。我现在已经切换到使用 Anaconda 和 Python 3.6 的 Windows,并且没有这样的问题。我第一时间就得到了正确的值。
法比安
关于python - MariaDB、Python read_sql_table、utf8-bin,我们在Stack Overflow上找到一个类似的问题: https://stackoverflow.com/questions/52999455/