我正在尝试编写一个全文搜索应用程序,该应用程序每 5 分钟索引近 10000 个传入文件。现在,在有人建议 Lucene、Solr、Sphinx、ElasticSearch 等之前,我不允许使用其中任何一个。所以我基本上是在尝试阅读有关建立索引的内容。具体来说,我被限制使用 MySQL(或任何其他 RDBMS)来存储索引(而不是文件)。
现在,我对 Lucene 的了解知之甚少,其核心运行的是倒排索引。我试图通过创建一个 word 数据库以及包含它们的相应文件来复制它。(我再次无法使用 Lucene 使用的文档)
我正在运行一个 cron 作业,它每 5 分钟检查一次新文件是否已上传并将它们放入队列中。对于队列,运行 Java 代码来创建索引并将其存储在 mysql 表中。当我们处理一些文件时,所有这些 FCFS 都很好。但由于每 5 分钟加载 10000 个文件,索引将花费大量时间。那么每次推送新文件时生成一个线程是最佳选择吗?这将导致我的服务器上运行数千个线程,而这些线程已经在执行其他任务。处理这项任务的最佳方法是什么?
我的另一个疑问是: 根据我的阅读,我了解到 Lucene 使用跳过列表来存储包含单词的文档列表。像这样的东西: http://4.bp.blogspot.com/-aAvEQEILnEc/USeg8wgdBqI/AAAAAAAAA-s/1D9sNkwVwkk/s1600/p1.png
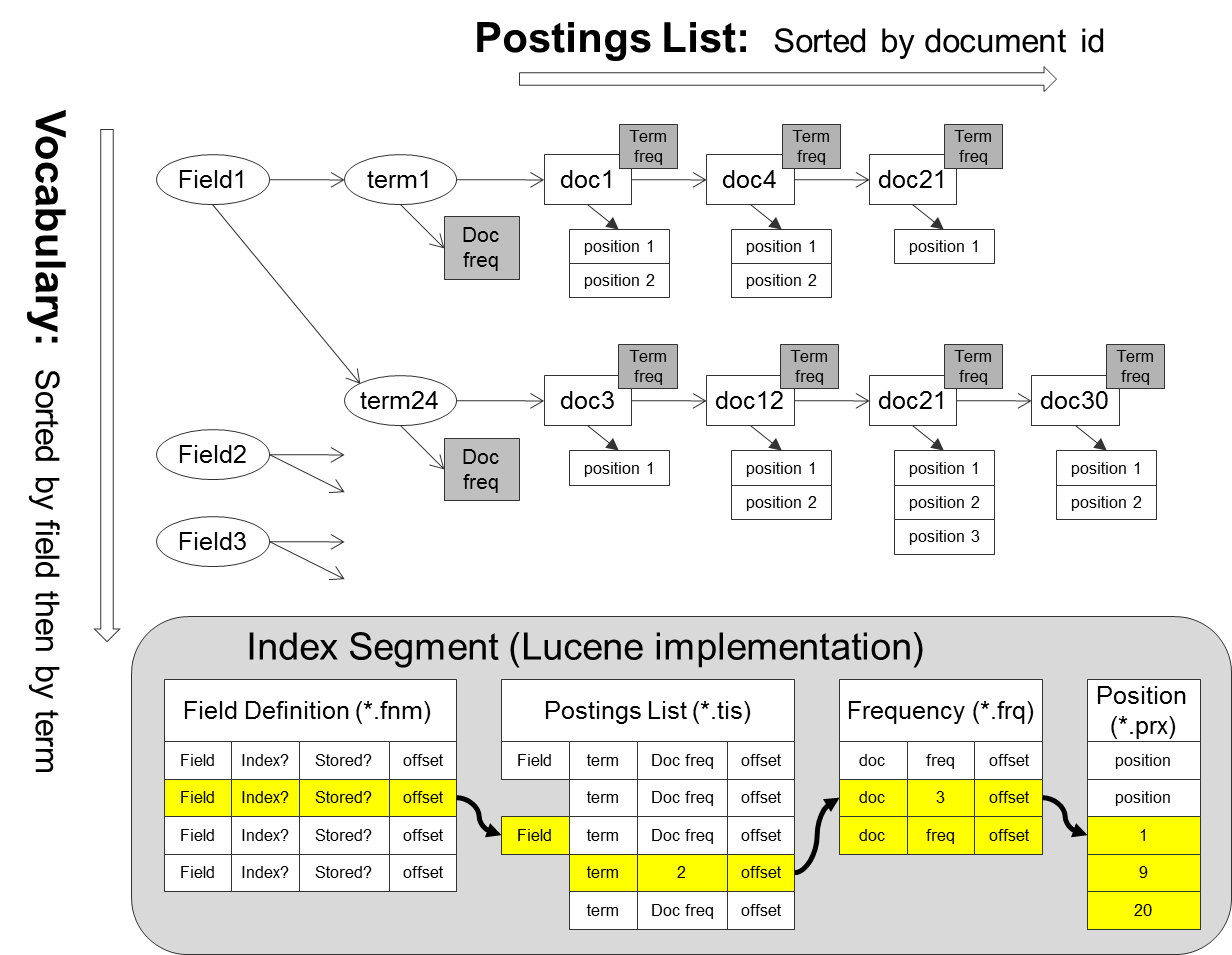{kind=link}
然而,由于使用 MySQL,我无法使用跳过列表,而是必须进行非规范化并面临大量冗余。有办法解决吗?
最佳答案
您必须将文件文本加载到 MySQL 表中才能完成此工作,然后创建 FULLTEXT 索引。
如果您想要创建一个方案来搜索文本并返回文件名,则可以使用这些列。
id (autoincrement)
filepath (path name for the file)
serialno (when whole file is too long for one filetext column, it can be split)
filetext text from the file.
请注意,可以使用 FULLTEXT 索引进行索引的列中的字符数有限制。如果将 filetext 列的长度限制为 700 个字符,应该没问题。这确实意味着,当您加载表格时,您必须将文件文本在字边界上拆分为该表格中的多行。
有一个停用词列表:未索引的单词。 http://dev.mysql.com/doc/refman/5.5/en/fulltext-stopwords.html
使用全文搜索应该对您来说效果还不错。如您所知,如果您想要高性能的文本搜索功能,Lucene 提供了很多 FULLTEXT 所没有的东西。
关于mysql - 对许多传入文件建立索引,我们在Stack Overflow上找到一个类似的问题: https://stackoverflow.com/questions/24513253/