我正在使用LOAD DATA LOCAL INFILE 来填充具有以下结构的表:
CREATE TABLE `player_talent` (
`player_id` int(10) unsigned NOT NULL,
`talent_id` int(10) unsigned NOT NULL,
`level` tinyint(4) NOT NULL,
PRIMARY KEY (`player_id`,`level`),
KEY `player_talent_talent_id_foreign` (`talent_id`),
CONSTRAINT `player_talent_player_id_foreign` FOREIGN KEY (`player_id`) REFERENCES `players` (`id`) ON DELETE CASCADE,
CONSTRAINT `player_talent_talent_id_foreign` FOREIGN KEY (`talent_id`) REFERENCES `talents` (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_ci
我在 Google 云上使用 MySQL 5.7,在导入之前,我禁用 binlog 并将 innodb_flush_log_at_trx_commit、unique_checks 和 foreign_key_checks 设置为 0
以下是加载数据时已用存储空间的样子:

IOPS 始终处于最大值。在上面的图像中,导入甚至没有完成。如果我删除所有索引,然后在导入后重新创建它们,则该图如下所示:
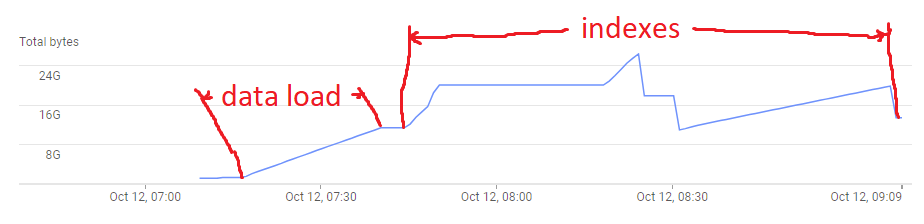
导入阶段具有一致的线性性能。重新创建索引比导入需要更长的时间,但至少它在合理的时间内完成。
有没有办法避免手动执行此操作?我认为 LOAD DATA 应该提供最佳的性能。 InnoDB 不支持 DISABLE KEYS
最佳答案
你说你有 250M 行,这对于要求 MySQL 在单个语句中插入来说是很多。为了提高提取性能,我建议您将输入拆分为多个文件。
我blogged过去关于这个问题的信息,以及一些快捷方式,可以更轻松地将文件分成更小的部分。我想说每个文件应该有 100 万行或更小。
关于mysql - 当表有索引时,LOAD DATA 的速度呈指数减慢,我们在Stack Overflow上找到一个类似的问题: https://stackoverflow.com/questions/46707858/