<分区>
regex - 需要从批处理中的 epub 或文本文件中提取一组 4 位数字
我有数百个 epub 文件。我需要从带有文件名的文本中提取日期(只有 1947 年、1987 年等年份) 我的意思是,输出应该是这样的,这个文件名包含这个日期等等 例如 epub01 包含 1995 1945 1986。 epub02 包含 1926 1946 1948。 如果有人能为我提供一个 PowerShell 脚本或可以在 ubuntu 终端中运行的脚本,那就太好了。
虽然我有 epub 文件,但我可以自己提取到文本文件。如果您有文本文件的脚本。
最佳答案
我只能提供文本文件的脚本。您可以使用 Get-Content cmdlet 读取它们,并使用 regex 获取包含负前瞻和负后瞻的值,以确保恰好有四位数字:
$content = Get-Content 'your_file' -Raw
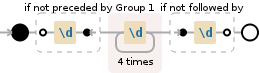
$matches = [regex]::Matches($content, '(?<!\d)(\d{4})(?!\d)')
$matches | ForEach-Object {
$_.Groups[1].Value
}
正则表达式解释:
(?<!\d)(\d{4})(?!\d)
关于regex - 需要从批处理中的 epub 或文本文件中提取一组 4 位数字,我们在Stack Overflow上找到一个类似的问题: https://stackoverflow.com/questions/38785308/