有人介意就这张 table 的设置给我建议吗。
第一次设计数据库。这将是其中的一部分。
它是一个报告编写应用程序。可以指派多位工程师参加任何工作/报告,多位工程师可以在参加的同时撰写报告。
这是最好的方法吗?我需要能够在应用程序中分别搜索与会者和作者。
非常感谢您的帮助。
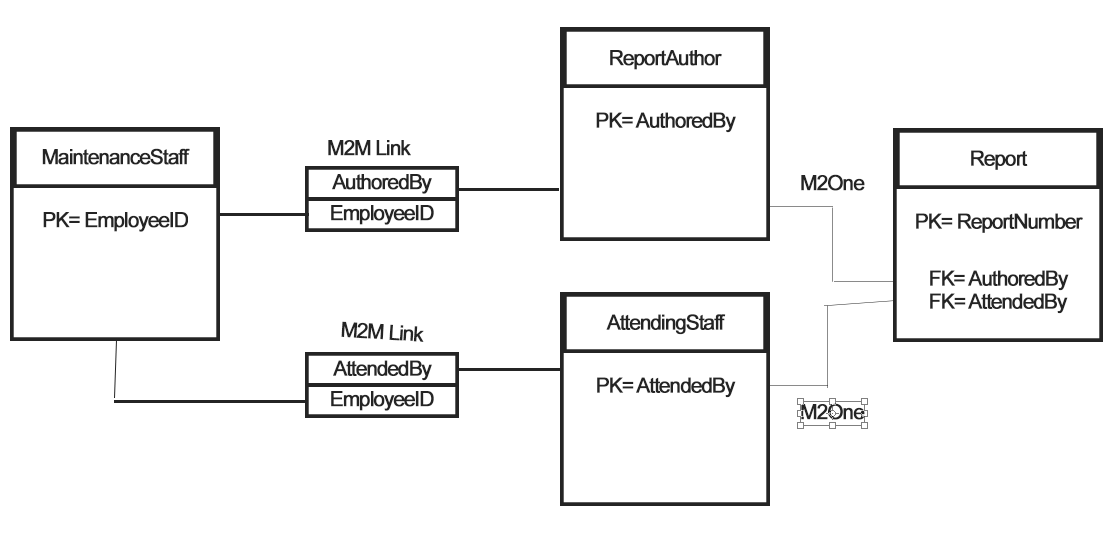
最佳答案
我相信您有两个包含实体的表。实体是 employee 和 report。
这些实体有两种不同的多对多关系:author 和 attendee。
所以你的表是这些
employee report
-------- -----
employee_id (PK) report_id (PK)
surname title
givenname releasedate
whatever whatever
然后你有两个多对多关系表,它们的列相同。一个是 author,另一个是 attendee。
author / attendee
------
employee_id PK, FK to employee.employee_id
report_id PK, FK to report.report_id
注意复合(两列)主键。
+---------------------+\ /+-------------+\ /+-----------------------+
| +-----+ author +-----+ |
| |/ \+-------------+/ \| |
| employee | | report |
| | | |
| |\ /+-------------+\ /| |
| +-----+ attendee +-----+ |
+---------------------+/ \+-------------+/ \+-----------------------+
\ /
----- means a many-to-many relationship
/ \
当您确定员工是某个报告的参加者时,您可以在参加者表中插入一行,其中包含正确的员工和报告。
例如,如果您想要每份报告的所有作者,您可以这样做:
SELECT r.title, r.releasedate,
GROUP_CONCAT(e.surname ORDER BY e.surname SEPARATED BY ',')surnames
FROM report r
LEFT JOIN author a ON r.report_id = a.report_id
LEFT JOIN employee e ON a.report_id = e.report_id
GROUP BY r.title, r.releasedate
ORDER BY r.releasedate DESC
LEFT JOIN 操作允许您的查询查找没有作者的报告。普通的内部 JOIN 操作会从结果集中抑制这些行。
这种严格的 E:R 设计存在局限性。对于许多类型的报告(例如科学论文),作者的顺序至关重要。 (你想发起一场学术食物大战?以错误的顺序列出论文的作者。)
因此您的 author 表可能还包含一个序数值。
author
------
employee_id PK, FK to employee.employee_id
report_id PK, FK to report.report_id
ordinal INT
并且您的报告查询将包含这一行。
GROUP_CONCAT(e.surname ORDER BY e.ordinal SEPARATED BY ',')surnames
关于MySQL - 建议链接多个表 - 这是正确的吗?,我们在Stack Overflow上找到一个类似的问题: https://stackoverflow.com/questions/53170283/