我一直在尝试使用 Scrapy-Selenium 解析 NYTimes 页面。页面链接:https://www.nytimes.com/2019/03/21/travel/what-to-do-in-hoi-an-vietnam.html
据我所知,这是一个 javascript 驱动的页面。当我借助 Chrome 浏览器扩展禁用 javascript 时,我看到灰色占位符而不是一些照片。
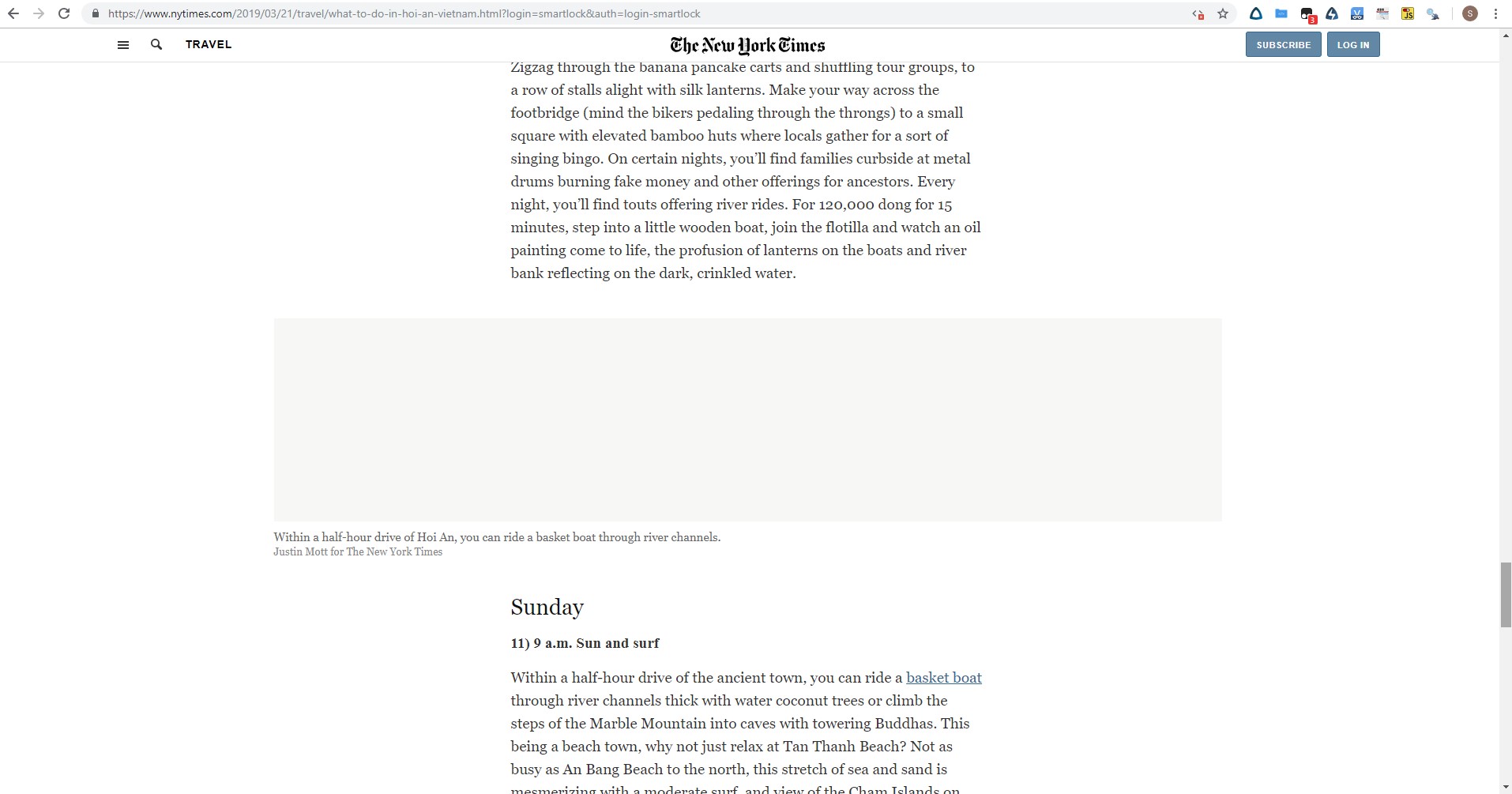
Javascript 已启用
 禁用Javascript
禁用Javascript
以下片段是启用了 JS 的图像:
<div data-testid="lazyimage-container" style="height: auto; cursor: pointer;">
<img alt="" class="css-1h6w7uo e1t57l6r0" src="https://static01.nyt.com/images/2019/03/21/travel/21Hours-Hoi-An1/merlin_151549596_96de6b6d-174d-4cdb-add2-b77b5612ffab-articleLarge.jpg?quality=75&auto=webp&disable=upscale" srcset="https://static01.nyt.com/images/2019/03/21/travel/21Hours-Hoi-An1/merlin_151549596_96de6b6d-174d-4cdb-add2-b77b5612ffab-articleLarge.jpg?quality=90&auto=webp 600w,https://static01.nyt.com/images/2019/03/21/travel/21Hours-Hoi-An1/merlin_151549596_96de6b6d-174d-4cdb-add2-b77b5612ffab-jumbo.jpg?quality=90&auto=webp 1024w,https://static01.nyt.com/images/2019/03/21/travel/21Hours-Hoi-An1/merlin_151549596_96de6b6d-174d-4cdb-add2-b77b5612ffab-superJumbo.jpg?quality=90&auto=webp 2048w" sizes="((min-width: 600px) and (max-width: 1004px)) 84vw, (min-width: 1005px) 80vw, 100vw" itemprop="url" itemid="https://static01.nyt.com/images/2019/03/21/travel/21Hours-Hoi-An1/merlin_151549596_96de6b6d-174d-4cdb-add2-b77b5612ffab-articleLarge.jpg?quality=75&auto=webp&disable=upscale" style="opacity: 1;">
</div>
没有 JS 就只有 div:
<div data-testid="lazyimage-container" style="height:257.77777777777777px"></div>
我的 Scrapy 蜘蛛:
import scrapy
from scrapy_selenium import SeleniumRequest
from pprint import pprint
class NytimesSpider(scrapy.Spider):
name = "nyt"
start_urls = ["https://www.nytimes.com/2019/03/21/travel/what-to-do-in-hoi-an-vietnam.html"]
def start_requests(self):
for url in self.start_urls:
yield SeleniumRequest(url=url, callback=self.parse_result)
def parse_result(self, response):
print("=" * 60)
imgs = response.css("img::attr(src)").getall()
for img in imgs:
print(img)
print("")
print("=" * 60)
输出:
============================================================
https://static01.nyt.com/images/2019/03/24/travel/21Hours-Hoi-An6/merlin_151545219_ba2c9daa-c40a-4d52-80fe-ba679f3a98c2-articleLarge.jpg?quality=75&auto=webp&disable=upscale
https://static01.nyt.com/images/2019/03/24/travel/21Hours-Hoi-An6/merlin_151545219_ba2c9daa-c40a-4d52-80fe-ba679f3a98c2-articleLarge.jpg?quality=75&auto=webp&disable=upscale
https://static01.nyt.com/images/2018/02/25/travel/25vietnam1/merlin_133277466_698b9b08-f2d5-43c4-a44e-978ddc23cbac-videoLarge.jpg
https://static01.nyt.com/images/2018/12/26/travel/26PTG-LAOS-COMBO-promo/26PTG-LAOS-COMBO-promo-threeByTwoSmallAt2X-v6.jpg
https://static01.nyt.com/images/2019/03/21/travel/21Hours-Hoi-An2/merlin_151543719_ee268c49-2cac-47a6-855c-dedcb8fc7676-articleLarge.jpg?quality=75&auto=webp&disable=upscale
https://static01.nyt.com/images/2019/01/07/travel/52-PROMO/52-PROMO-articleLarge.jpg
https://mwcm.nyt.com/dam/mkt_assets/exo/img/nyt-logo-379x64.svg
https://et.nytimes.com/pixel?url=https://www.nytimes.com/2019/03/21/travel/what-to-do-in-hoi-an-vietnam.html&referrer=&subject=module-interactions&moduleData=%7B%22module%22%3A%22nyt-vi-page-pixel%22%2C%22pgType%22%3A%22%22%2C%22eventName%22%3A%22Impression%22%2C%22action%22%3A%22Impression%22%7D&sourceApp=nyt-vi&instant=1&_=1553234896724
https://et.nytimes.com/pixel.gif?subject=ab-expose&test=PER_MoreIn_World&variant=3_au_most_popular&url=https%3A%2F%2Fwww.nytimes.com%2F2019%2F03%2F21%2Ftravel%2Fwhat-to-do-in-hoi-an-vietnam.html&instant=1&skipAugment=true>m=GTM-P528B3-284-Production&et2_pageview_id=yrkmw_cn5c1oW40tVV_VdoTl
============================================================
问题是结果列表中没有所需的图片。照片来源是https://static01.nyt.com/images/2019/03/21/travel/21Hours-Hoi-An1/merlin_151549596_96de6b6d-174d-4cdb-add2-b77b5612ffab-articleLarge.jpg?quality=75&auto=webp&disable=upscale
{kind=link}
整个命令行日志是:
(nlp2) D:\Python\_Project\Scraping_train_data\snyt>scrapy crawl nyt
2019-03-22 09:08:11 [scrapy.utils.log] INFO: Scrapy 1.5.2 started (bot: snyt)
2019-03-22 09:08:11 [scrapy.utils.log] INFO: Versions: lxml 4.3.2.0, libxml2 2.9.8, cssselect 1.0.3, parsel 1.5.1, w3lib 1.20.0, Twisted 18.9.0, Python 3.7.2 (default, Feb 21 2019, 17:35:59) [MSC v.1915 64 bit (AMD64)], pyOpenSSL 19.0.0 (OpenSSL 1.1.1b 26 Feb 2019), cryptography 2.5, Platform Windows-10-10.0.17763-SP0
2019-03-22 09:08:11 [scrapy.crawler] INFO: Overridden settings: {'BOT_NAME': 'snyt', 'NEWSPIDER_MODULE': 'snyt.spiders', 'SPIDER_MODULES': ['snyt.spiders']}
2019-03-22 09:08:11 [scrapy.extensions.telnet] INFO: Telnet Password: 4d9b971e8de9258e
2019-03-22 09:08:11 [scrapy.middleware] INFO: Enabled extensions:
['scrapy.extensions.corestats.CoreStats',
'scrapy.extensions.telnet.TelnetConsole',
'scrapy.extensions.logstats.LogStats']
2019-03-22 09:08:14 [selenium.webdriver.remote.remote_connection] DEBUG: POST http://127.0.0.1:56203/session {"capabilities": {"firstMatch": [{}], "alwaysMatch": {"browserName": "firefox", "acceptInsecureCerts": true, "moz:firefoxOptions": {"args": ["--headless"]}}}, "desiredCapabilities": {"browserName": "firefox", "acceptInsecureCerts": true, "marionette": true, "moz:firefoxOptions": {"args": ["--headless"]}}}
2019-03-22 09:08:14 [urllib3.connectionpool] DEBUG: Starting new HTTP connection (1): 127.0.0.1:56203
2019-03-22 09:08:16 [urllib3.connectionpool] DEBUG: http://127.0.0.1:56203 "POST /session HTTP/1.1" 200 702
2019-03-22 09:08:16 [selenium.webdriver.remote.remote_connection] DEBUG: Finished Request
2019-03-22 09:08:16 [scrapy.middleware] INFO: Enabled downloader middlewares:
['scrapy.downloadermiddlewares.httpauth.HttpAuthMiddleware',
'scrapy.downloadermiddlewares.downloadtimeout.DownloadTimeoutMiddleware',
'scrapy.downloadermiddlewares.defaultheaders.DefaultHeadersMiddleware',
'scrapy.downloadermiddlewares.useragent.UserAgentMiddleware',
'scrapy.downloadermiddlewares.retry.RetryMiddleware',
'scrapy.downloadermiddlewares.redirect.MetaRefreshMiddleware',
'scrapy.downloadermiddlewares.httpcompression.HttpCompressionMiddleware',
'scrapy.downloadermiddlewares.redirect.RedirectMiddleware',
'scrapy.downloadermiddlewares.cookies.CookiesMiddleware',
'scrapy.downloadermiddlewares.httpproxy.HttpProxyMiddleware',
'scrapy_selenium.SeleniumMiddleware',
'scrapy.downloadermiddlewares.stats.DownloaderStats']
2019-03-22 09:08:16 [scrapy.middleware] INFO: Enabled spider middlewares:
['scrapy.spidermiddlewares.httperror.HttpErrorMiddleware',
'scrapy.spidermiddlewares.offsite.OffsiteMiddleware',
'scrapy.spidermiddlewares.referer.RefererMiddleware',
'scrapy.spidermiddlewares.urllength.UrlLengthMiddleware',
'scrapy.spidermiddlewares.depth.DepthMiddleware']
2019-03-22 09:08:16 [scrapy.middleware] INFO: Enabled item pipelines:
[]
2019-03-22 09:08:16 [scrapy.core.engine] INFO: Spider opened
2019-03-22 09:08:16 [scrapy.extensions.logstats] INFO: Crawled 0 pages (at 0 pages/min), scraped 0 items (at 0 items/min)
2019-03-22 09:08:16 [scrapy.extensions.telnet] DEBUG: Telnet console listening on 127.0.0.1:6023
2019-03-22 09:08:16 [selenium.webdriver.remote.remote_connection] DEBUG: POST http://127.0.0.1:56203/session/fa7fe711-db01-4b58-8d86-2efd31b23529/url {"url": "https://www.nytimes.com/2019/03/21/travel/what-to-do-in-hoi-an-vietnam.html"}
2019-03-22 09:08:24 [urllib3.connectionpool] DEBUG: http://127.0.0.1:56203 "POST /session/fa7fe711-db01-4b58-8d86-2efd31b23529/url HTTP/1.1" 200 14
2019-03-22 09:08:24 [selenium.webdriver.remote.remote_connection] DEBUG: Finished Request
2019-03-22 09:08:24 [selenium.webdriver.remote.remote_connection] DEBUG: GET http://127.0.0.1:56203/session/fa7fe711-db01-4b58-8d86-2efd31b23529/source {}
2019-03-22 09:08:24 [urllib3.connectionpool] DEBUG: http://127.0.0.1:56203 "GET /session/fa7fe711-db01-4b58-8d86-2efd31b23529/source HTTP/1.1" 200 1971834
2019-03-22 09:08:24 [selenium.webdriver.remote.remote_connection] DEBUG: Finished Request
2019-03-22 09:08:24 [selenium.webdriver.remote.remote_connection] DEBUG: GET http://127.0.0.1:56203/session/fa7fe711-db01-4b58-8d86-2efd31b23529/url {}
2019-03-22 09:08:24 [urllib3.connectionpool] DEBUG: http://127.0.0.1:56203 "GET /session/fa7fe711-db01-4b58-8d86-2efd31b23529/url HTTP/1.1" 200 87
2019-03-22 09:08:24 [selenium.webdriver.remote.remote_connection] DEBUG: Finished Request
2019-03-22 09:08:24 [scrapy.core.engine] DEBUG: Crawled (200) <GET https://www.nytimes.com/2019/03/21/travel/what-to-do-in-hoi-an-vietnam.html> (referer: None)
============================================================
https://static01.nyt.com/images/2019/03/24/travel/21Hours-Hoi-An6/merlin_151545219_ba2c9daa-c40a-4d52-80fe-ba679f3a98c2-articleLarge.jpg?quality=75&auto=webp&disable=upscale
https://static01.nyt.com/images/2019/03/24/travel/21Hours-Hoi-An6/merlin_151545219_ba2c9daa-c40a-4d52-80fe-ba679f3a98c2-articleLarge.jpg?quality=75&auto=webp&disable=upscale
https://static01.nyt.com/images/2018/02/25/travel/25vietnam1/merlin_133277466_698b9b08-f2d5-43c4-a44e-978ddc23cbac-videoLarge.jpg
https://static01.nyt.com/images/2018/12/26/travel/26PTG-LAOS-COMBO-promo/26PTG-LAOS-COMBO-promo-threeByTwoSmallAt2X-v6.jpg
https://static01.nyt.com/images/2019/03/21/travel/21Hours-Hoi-An2/merlin_151543719_ee268c49-2cac-47a6-855c-dedcb8fc7676-articleLarge.jpg?quality=75&auto=webp&disable=upscale
https://static01.nyt.com/images/2019/01/07/travel/52-PROMO/52-PROMO-articleLarge.jpg
https://mwcm.nyt.com/dam/mkt_assets/exo/img/nyt-logo-379x64.svg
https://et.nytimes.com/pixel?url=https://www.nytimes.com/2019/03/21/travel/what-to-do-in-hoi-an-vietnam.html&referrer=&subject=module-interactions&moduleData=%7B%22module%22%3A%22nyt-vi-page-pixel%22%2C%22pgType%22%3A%22%22%2C%22eventName%22%3A%22Impression%22%2C%22action%22%3A%22Impression%22%7D&sourceApp=nyt-vi&instant=1&_=1553234896724
https://et.nytimes.com/pixel.gif?subject=ab-expose&test=PER_MoreIn_World&variant=3_au_most_popular&url=https%3A%2F%2Fwww.nytimes.com%2F2019%2F03%2F21%2Ftravel%2Fwhat-to-do-in-hoi-an-vietnam.html&instant=1&skipAugment=true>m=GTM-P528B3-284-Production&et2_pageview_id=yrkmw_cn5c1oW40tVV_VdoTl
============================================================
2019-03-22 09:08:25 [scrapy.core.engine] INFO: Closing spider (finished)
2019-03-22 09:08:25 [selenium.webdriver.remote.remote_connection] DEBUG: DELETE http://127.0.0.1:56203/session/fa7fe711-db01-4b58-8d86-2efd31b23529 {}
2019-03-22 09:08:26 [urllib3.connectionpool] DEBUG: http://127.0.0.1:56203 "DELETE /session/fa7fe711-db01-4b58-8d86-2efd31b23529 HTTP/1.1" 200 14
2019-03-22 09:08:26 [selenium.webdriver.remote.remote_connection] DEBUG: Finished Request
2019-03-22 09:08:26 [scrapy.statscollectors] INFO: Dumping Scrapy stats:
{'downloader/response_bytes': 1915145,
'downloader/response_count': 1,
'downloader/response_status_count/200': 1,
'finish_reason': 'finished',
'finish_time': datetime.datetime(2019, 3, 22, 6, 8, 25, 30708),
'log_count/DEBUG': 18,
'log_count/INFO': 8,
'response_received_count': 1,
'scheduler/dequeued': 1,
'scheduler/dequeued/memory': 1,
'scheduler/enqueued': 1,
'scheduler/enqueued/memory': 1,
'start_time': datetime.datetime(2019, 3, 22, 6, 8, 16, 33466)}
2019-03-22 09:08:26 [scrapy.core.engine] INFO: Spider closed (finished)
我根据说明(https://github.com/clemfromspace/scrapy-selenium)将这些行添加到 settings.py:
from shutil import which
SELENIUM_DRIVER_NAME = 'firefox'
SELENIUM_DRIVER_EXECUTABLE_PATH = which('geckodriver')
SELENIUM_DRIVER_ARGUMENTS=['--headless']
DOWNLOADER_MIDDLEWARES = {
'scrapy_selenium.SeleniumMiddleware': 800
}
我不熟悉抓取基于 javascript 的网站,但我已经成功解析了 https://edition.cnn.com/search/?q=war带有 Scrapy-Selenium 的页面。应该是Scrapy项目设置对吧。
我哪里错了,为什么蜘蛛看不到所有的图片?
提前谢谢你。
最佳答案
您需要的照片是带有 aria-label="media" 属性的 figure 标签。您可以使用选择器获取图像链接并获取包含图像 url 的 itemid 属性。
这是 HTML:
<figure class="css-kyszhr e1g7ppur0" aria-label="media" role="group"
itemProp="associatedMedia" itemscope=""
itemID="https://static01.nyt.com/images/2019/03/21/travel/21Hours-Hoi-An5/merlin_151541649_b7b94eb2-7166-4849-ba4e-a93343607370-articleLarge.jpg?quality=90&auto=webp"
itemType="http://schema.org/ImageObject">
<div class="css-1xdhyk6 erfvjey0"><span class="css-1ly73wi e1tej78p0">Image</span>
<div class="css-zjzyr8">
<div data-testid="lazyimage-container"
style="height:257.77777777777777px"></div>
</div>
</div>
<figcaption itemProp="caption description" class="css-1l6g02d e1xdpqjp0"><span
class="css-8i9d0s e13ogyst0">Tadioto, an elegant new whisky bar in the French Quarter, is hidden behind a clothing boutique.</span><span
itemProp="copyrightHolder" class="css-vuqh7u e1z0qqy90"><span
class="css-1ly73wi e1tej78p0">Credit</span><span>Justin Mott for The New York Times</span></span>
</figcaption>
</figure>
你也可以尝试使用requests和BeautifulSoup来抓取:
import requests
from bs4 import BeautifulSoup
headers = {
'authority': 'www.nytimes.com',
'pragma': 'no-cache',
'cache-control': 'no-cache',
'upgrade-insecure-requests': '1',
'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_3) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/73.0.3683.75 Safari/537.36',
'dnt': '1',
'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,'
'application/signed-exchange;v=b3',
'accept-encoding': 'gzip, deflate, br',
'accept-language': 'ru,en-US;q=0.9,en;q=0.8,tr;q=0.7',
}
response = requests.get('https://www.nytimes.com/2019/03/21/travel/what-to-do-in-hoi-an-vietnam.html', headers=headers)
page = BeautifulSoup(response.text, "html.parser")
figures = page.find_all("figure", {"aria-label": "media"})
for figure in figures:
print(figure.attrs["itemid"])
images = page.find_all("img")
for image in images:
print(image.attrs["src"])
print("the end")
关于javascript - Scrapy-Selenium 纽约时报问题,我们在Stack Overflow上找到一个类似的问题: https://stackoverflow.com/questions/55294284/