我正在创建基于 Java 的 OCR。我的目标是从视频文件中提取文本(后处理)。
要找到完全在 Java 上运行的免费开源 OCR,这是一项艰巨的搜索工作。我发现 Tess4J 是唯一受欢迎的选择,但考虑到对 native 接口(interface)的需求,我不知何故倾向于从头开发算法。
我需要创建一个可靠的 OCR,以合理的准确度正确识别英文字母(仅计算机化字体,而不是手写文本),前提是文本在视频帧中的区域是预定义的。我们也可以假设文本的颜色是给定的。
到目前为止我做了什么:
(所有图像处理都使用 openCV 的 Java 绑定(bind)完成)
我使用以下方法提取了用于训练我的分类器的特征:
一个。将字符图像下采样到 12 X 12 分辨率后的像素强度。 (144个特征向量)
B.跨越 8 个不同角度(0、11.25、22.5 ...等)的 Gabor 小波变换和使用所有这些角度的信号的均方值计算的能量。 (8个特征向量)
A+B 给出图像的特征向量。 (共152个特征向量)
我有 62 个分类类,即。 0,1,2...9 | a,b,c,d...y,z | A,B,C,D...Y,Z
我使用 20 x 62 个样本(每个类 20 个)训练分类器。
对于分类,我使用了以下两种方法:
一个。具有 1 个隐藏层(120 个节点)的 ANN。输入层有 152 个节点,输出有 62 个。隐藏层和输出层具有 sigmoid 激活函数,网络使用弹性反向传播进行训练。
B.整个 152 个维度的 kNN 分类。
我的立场:
k 最近邻搜索被证明是比神经网络更好的分类器(到目前为止)。但是,即使使用 kNN,我也发现很难对以下字母进行分类:
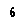 或者
或者  .
.
此外,它正在分类 作为 Z... 仅举几例异常。
作为 Z... 仅举几例异常。
我在找什么:
我想了解以下内容:
为什么 ANN 表现不佳?我应该使用什么网络配置来提高性能?我们能否对 ANN 进行微调以使其性能优于 kNN 搜索?
我可以使用哪些其他特征向量来提高 OCR 的鲁棒性?
欢迎提出任何其他性能优化建议。
最佳答案
kNN 算法不需要大量调整,不像神经网络,因此您可以轻松获得良好的性能,但多层感知器可能优于 kNN。目前,我认为最好的结果是使用深度学习来达到的,例如你应该看看卷积神经网络。
来自维基百科:
A CNN is composed of one or more convolutional layers with fully connected layers (matching those in typical artificial neural networks) on top. It also uses tied weights and pooling layers. This architecture allows CNNs to take advantage of the 2D structure of input data. In comparison with other deep architectures, convolutional neural networks are starting to show superior results in both image and speech applications. They can also be trained with standard backpropagation. CNNs are easier to train than other regular, deep, feed-forward neural networks and have many fewer parameters to estimate, making them a highly attractive architecture to use.
谈到您的 MLP,有很多算法可以搜索更好的参数,例如网格搜索或群优化。我喜欢使用遗传算法来调整神经网络的参数,它非常简单并且性能良好。
我推荐你JGap ,一个很好的java遗传算法框架,可以开箱即用:)
这是 JGAP 对遗传算法的介绍,它比我的任何介绍都好:
Genetic algorithms (GA's) are search algorithms that work via the process of natural selection. They begin with a sample set of potential solutions which then evolves toward a set of more optimal solutions. Within the sample set, solutions that are poor tend to die out while better solutions mate and propagate their advantageous traits, thus introducing more solutions into the set that boast greater potential (the total set size remains constant; for each new solution added, an old one is removed). A little random mutation helps guarantee that a set won't stagnate and simply fill up with numerous copies of the same solution.
In general, genetic algorithms tend to work better than traditional optimization algorithms because they're less likely to be led astray by local optima. This is because they don't make use of single-point transition rules to move from one single instance in the solution space to another. Instead, GA's take advantage of an entire set of solutions spread throughout the solution space, all of which are experimenting upon many potential optima.
However, in order for genetic algorithms to work effectively, a few criteria must be met:
It must be relatively easy to evaluate how "good" a potential solution is relative to other potential solutions.
It must be possible to break a potential solution into discrete parts that can vary independently. These parts become the "genes" in the genetic algorithm.
Finally, genetic algorithms are best suited for situations where a "good" answer will suffice, even if it's not the absolute best answer.
关于java - OCR算法改进,我们在Stack Overflow上找到一个类似的问题: https://stackoverflow.com/questions/23871459/