我想将硬盘上的一个大 fortran 记录 (12G) 映射到一个 numpy 数组。 (映射而不是加载以节省内存。)
存储在fortran record中的数据是不连续的,因为它被记录标记分开了。记录结构为“标记、数据、标记、数据、...、数据、标记”。数据区域和标记的长度是已知的。
标记之间的数据长度不是4字节的倍数,否则我可以将每个数据区域映射到一个数组。
在memmap中设置offset可以跳过第一个标记,是否可以跳过其他标记并将数据映射到数组?
对于可能出现的歧义表达表示歉意,并感谢任何解决方案或建议。
5 月 15 日编辑
这些是 Fortran 未格式化的文件。 record中存储的数据是一个(1024^3)*3 float32数组(12Gb)。
大于2G的变长记录结构如下图所示:
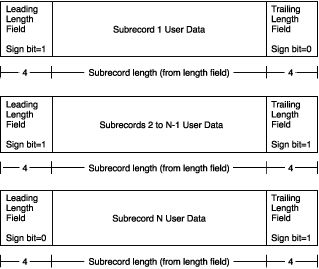
(有关详细信息,请参阅 here -> [记录类型] -> [可变长度记录] 部分。)
在我的例子中,除了最后一个,每个子记录的长度为 2147483639 字节并以 8 个字节分隔(如上图所示,前一个子记录的结束标记和下一个子记录的开始标记,总共 8 个字节)。
我们可以看到第一个子记录以某个 float 的前 3 个字节结束,第二个子记录以剩余的 1 个字节开始,如 2147483639 mod 4 =3。
最佳答案
我发布了另一个答案,因为 the example given here numpy.memmap 有效:
offset = 0
data1 = np.memmap('tmp', dtype='i', mode='r+', order='F',
offset=0, shape=(size1))
offset += size1*byte_size
data2 = np.memmap('tmp', dtype='i', mode='r+', order='F',
offset=offset, shape=(size2))
offset += size1*byte_size
data3 = np.memmap('tmp', dtype='i', mode='r+', order='F',
offset=offset, shape=(size3))
对于int32 byte_size=32/8,对于int16 byte_size=16/8 等等。 ..
如果大小不变,您可以将数据加载到二维数组中,例如:
shape = (total_length/size,size)
data = np.memmap('tmp', dtype='i', mode='r+', order='F', shape=shape)
您可以根据需要更改memmap 对象。甚至可以让数组共享相同的元素。在这种情况下,对一个所做的更改会自动更新到另一个。
其他引用:
关于python - 是否可以使用 python 将磁盘上的不连续数据映射到数组?,我们在Stack Overflow上找到一个类似的问题: https://stackoverflow.com/questions/16515465/