在我的测试 ELK 集群上,我在尝试查看上周的数据时遇到以下错误。
Data too large, data for [@timestamp] would be larger than limit
关于分片失败的警告似乎具有误导性,因为 elasticsearch 监控工具 kopf 和 head 显示所有分片都在正常工作,并且弹性集群是绿色的。
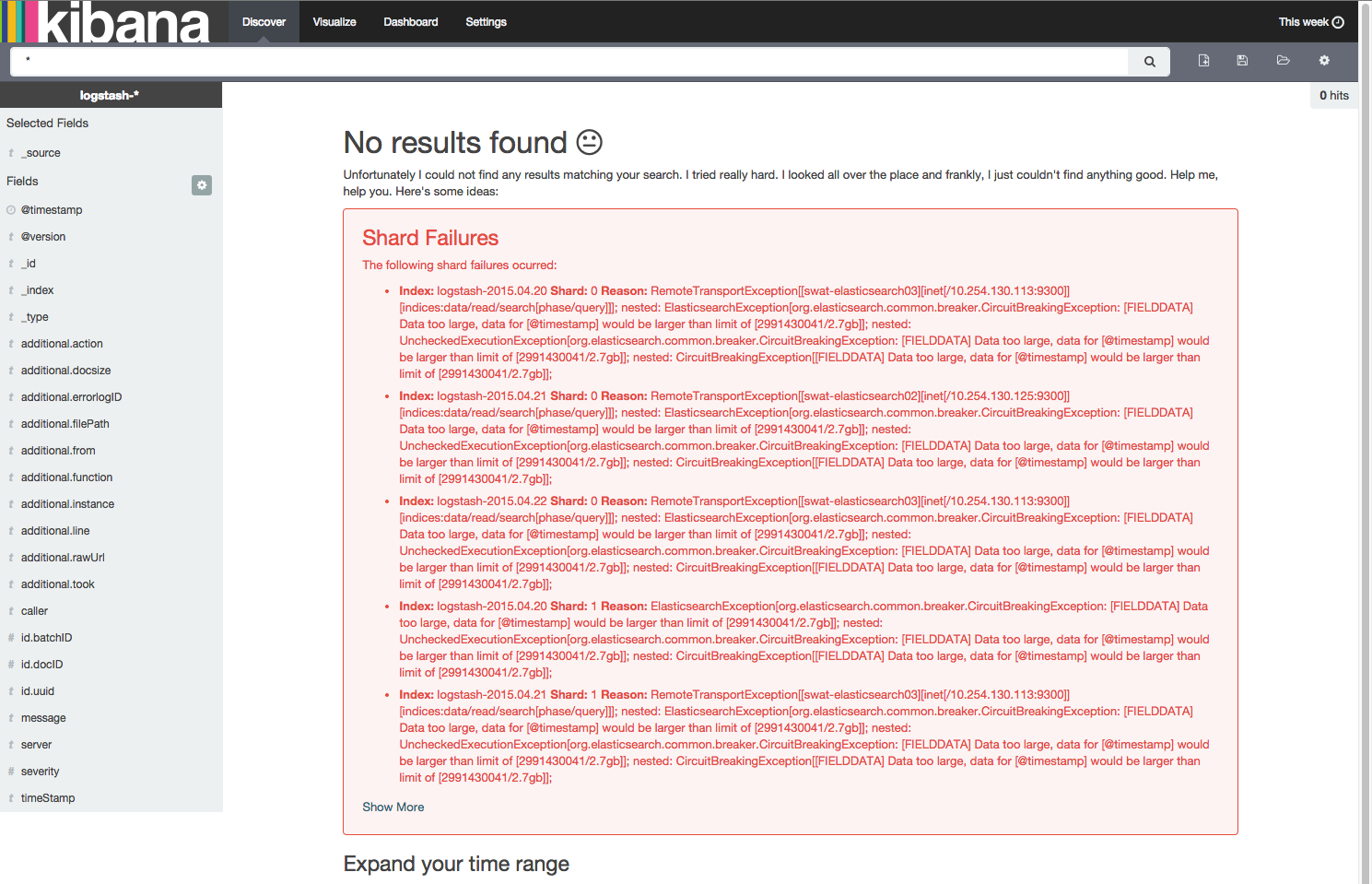
elasticsearch 的 google 组中的一位用户建议增加 ram。我已将 3 个节点增加到 8GB,每个节点有 4.7GB 堆,但问题仍然存在。 我每天生成大约 5GB 到 25GB 的数据,并保留 30 天。
最佳答案
清除缓存可以暂时缓解症状。
http://www.elastic.co/guide/en/elasticsearch/reference/current/indices-clearcache.html
清除单个索引
curl -XPOST 'http://localhost:9200/twitter/_cache/clear'
清除多个指标
curl -XPOST 'http://localhost:9200/kimchy,elasticsearch/_cache/clear'
curl -XPOST 'http://localhost:9200/_cache/clear'
或者按照 IRC 中用户的建议。这个似乎效果最好。
curl -XPOST 'http://localhost:9200/_cache/clear' -d '{ "fielddata": "true" }'
更新:一旦集群移动到更快的管理程序,这些错误就消失了
关于kibana - elasticsearch/kibana 错误“数据太大,[@timestamp] 的数据将大于限制,我们在Stack Overflow上找到一个类似的问题: https://stackoverflow.com/questions/29810531/