我以前也被问过这个问题,但这次我想知道C++ 和C# 的编译器之间的区别。
数组的C#编码
static void Main(string[] args)
{
int n;
int[] ar = new int[50];
Console.Write("Enter the size of array= ");
n = int.Parse(Console.ReadLine());
for (int i = 0; i < n; i++)
{
ar[i] = int.Parse(Console.ReadLine());
}
for (int i = 0; i < n; i++)
{
Console.WriteLine("AR[" + i + "]=" + ar[i]);
}
Console.Read();
}
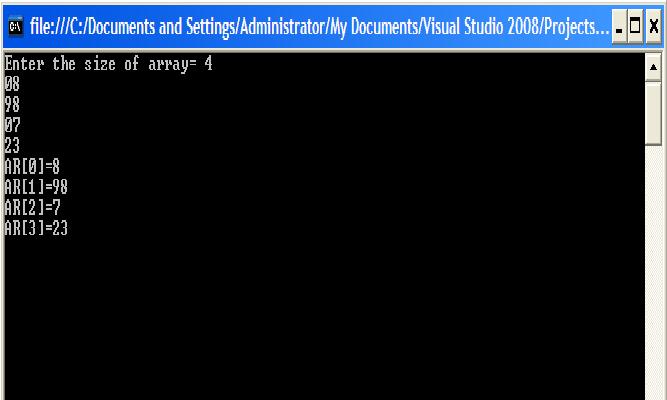
输出
数组的C++编码
int main()
{
clrscr();
int x[10];
int n;
cout << "Enter the array size= ";
cin >> n;
cout << "Enter the elements for array= ";
for(int i = 0; i < n; i++)
{
cin >> x[i];
}
for(int i = 0; i < n; i++)
{
cout << "x[" << i << "]=" << x[i] << "\n";
}
getch();
return 0;
}
输出
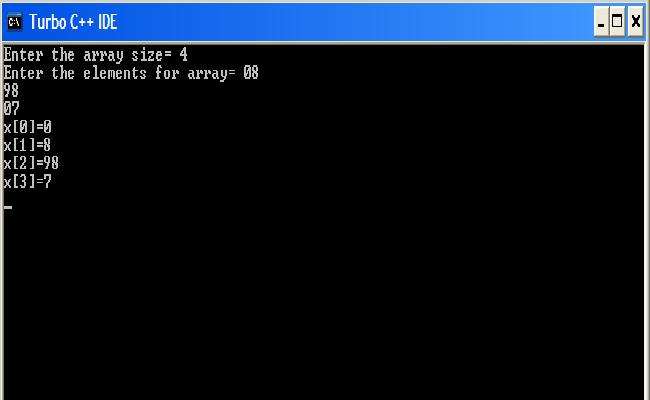
现在我的问题是,当 m 为 C# 提供相同的输入时,它要求输入 4 个元素并在任何数字前保留 0。但是当 m 在 C++ 中使用相同的输入时,它会将 0 与任何数字视为一个单独的输入,即使 m 给它一个数字并且输入的输入比我输入的少。
甚至两种语言都遵循 OOP 方法。那么这两个编译器之间有什么区别。为什么这些需要大量不同的输入并产生不同的输出。
另一个让我困扰的是,为什么 C++ 编译器不为最后一个元素读取 0 并打印 7,但我的输入是 07,所以根据上面的输出,它应该是 0 而不是 7。
最佳答案
这是一个完整的猜测,但 Borland C++ 试图将前导 0 的数字解释为八进制(这是一种标准约定,就像十六进制的 '0x' 前缀一样)。由于 08 不是有效的八进制数(只有 0-7 是八进制的有效数字),因此将其分成两个输入。
尝试输入“010”,如果程序打印出 8,您就会知道它将任何带前导零的内容解释为八进制。
您还可以尝试通过将输入行更改为以下内容来强制 cin 将您的输入解释为十进制:
cin >> dec >> x[i];
关于c# - 为什么 C++ 和 C# 编译器的输出不同?,我们在Stack Overflow上找到一个类似的问题: https://stackoverflow.com/questions/6638754/