如上所述,我一直在尝试设计一个简单的并行循环,但它对于不同数量的线程具有不一致的行为。这是我的代码(可测试!)
#include <iostream>
#include <stdio.h>
#include <vector>
#include <utility>
#include <string>
using namespace std;
int row = 5, col = 5;
int token = 1;
int ar[20][20] = {0};
int main (void)
{
unsigned short j_end = 1, k = 1;
unsigned short mask;
for (unsigned short i=1; i<=(row + col -1); i++)
{
#pragma omp parallel default(none) shared(ar) firstprivate(k, row, col, i, j_end, token) private(mask)
{
if(i > row) {
mask = row;
}
else {
mask = i;
}
#pragma omp for schedule(static, 2)
for(unsigned short j=k; j<=j_end; j++)
{
ar[mask][j] = token;
if(mask > 1) {
#pragma omp critical
{
mask--;
}
}
} //inner loop - barrier
}//end parallel
token++;
if(j_end == col) {
k++;
j_end = col;
}
else {
j_end++;
}
} // outer loop
// print the array
for (int i = 0; i < row + 2; i++)
{
for (int j = 0; j < col + 2; j++)
{
cout << ar[i][j] << " ";
}
cout << endl;
}
return 0;
} // main
我相信大部分代码都是不言自明的,但总而言之,我有 2 个循环,内部循环遍历方矩阵的反对角线 ar[row][col],(row 和 col 变量可用于更改 ar 的总大小)。
视觉辅助:5x5 ar 所需的输出(连续版)
(注意:当 OMP_NUM_THREADS=1 时也会发生这种情况。)
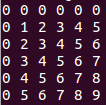
但是当 OMP_NUM_THREADS=2 或 OMP_NUM_THREADS=4 时,输出如下所示:

串行(和 1 个线程)代码是一致的,所以我认为实现没有问题。此外,鉴于串行代码的输出,内部循环中不应有任何依赖关系。
我也试过:
- 向量化
- 内循环的 threadpivate 计数器
但到目前为止似乎没有任何效果......
是我的方法有问题,还是我错过了导致这种行为的 API 方面的东西?
提前感谢您抽出时间。
最佳答案
分析算法
如您所述,算法本身在内部 或 外部循环中没有依赖性。证明这一点的一种简单方法是将并行性“向上”移动到外循环,以便您可以同时遍历所有不同的反对角线。
目前,您编写的算法的主要问题是它在内循环和外循环中都以串行算法的形式呈现。如果你要在内部循环中并行化,那么 mask需要特殊处理。如果要在外循环中并行化,则 j_end , token , 和 k需要特殊处理。通过“特殊处理”,我的意思是它们需要独立于其他线程进行计算。如果您尝试将关键区域添加到您的代码中,您将扼杀最初添加 OpenMP 带来的所有性能优势。
解决问题
在下面的代码中,我对外部循环进行了并行处理。 i对应你所说的token .也就是说,它既是要添加到反对角线的值,也是该对角线的假定起始长度。请注意,为了正确并行化,length , startRow , 和 startCol必须计算为 i 的函数独立于其他迭代。
最后请注意,一旦以这种方式重写了算法,实际的 OpenMP pragma 就非常简单了。默认情况下假定每个变量都是共享的,因为它们都是只读的。唯一的异常(exception)是 ar其中我们小心不要覆盖另一个线程的数组值。所有必须私有(private)的变量仅在并行循环内创建,因此根据定义是线程私有(private)的。最后,我将时间表更改为动态,以展示该算法表现出负载不平衡。在您的示例中,如果您有 9 个线程(最坏的情况),您可以看到线程如何分配给 i=5必须比分配给 i=1 的线程做更多的工作或 i=9 .
示例代码
#include <iostream>
#include <omp.h>
int row = 5;
int col = 5;
#define MAXSIZE 20
int ar[MAXSIZE][MAXSIZE] = {0};
int main(void)
{
// What an easy pragma!
#pragma omp parallel for default(shared) schedule(dynamic)
for (unsigned short i = 1; i < (row + col); i++)
{
// Calculates the length of the current diagonal to consider
// INDEPENDENTLY from other i iterations!
unsigned short length = i;
if (i > row) {
length -= (i-row);
}
if (i > col) {
length -= (i-col);
}
// Calculates the starting coordinate to start at
// INDEPENDENTLY from other i iterations!
unsigned short startRow = i;
unsigned short startCol = 1;
if (startRow > row) {
startCol += (startRow-row);
startRow = row;
}
for(unsigned short offset = 0; offset < length; offset++) {
ar[startRow-offset][startCol+offset] = i;
}
} // outer loop
// print the array
for (int i = 0; i <= row; i++)
{
for (int j = 0; j <= col; j++)
{
std::cout << ar[i][j] << " ";
}
std::cout << std::endl;
}
return 0;
} // main
最后的分数
我想留下最后几点。
- 如果您只是在小型阵列 (
row,col < 1e6) 上添加并行性,您很可能无法从 OpenMP 中获益。在小型阵列上,算法本身需要几微秒,而设置线程可能需要几毫秒……与原始串行代码相比,这会大大减慢执行时间! - 虽然我确实重写了这个算法并更改了变量名,但我尽量保持你的实现精神。因此,反对角线扫描和嵌套循环模式仍然存在。
- 不过,有一种更好的方法可以并行化此算法以避免负载平衡。相反,如果你给每个线程一行,让它迭代它的标记值(即行/线程 2 放置数字 2->6),那么每个线程将处理完全相同数量的数字,你可以将 pragma 更改为
schedule(static). - 正如我在上面的评论中提到的,不要使用
firstprivate当你说shared.一个好的经验法则是所有只读变量都应该是shared. - 假设在 1 个线程上运行并行代码时获得正确的输出就意味着实现是正确的,这是错误的。事实上,除非灾难性地使用 OpenMP,否则你不太可能只用 1 个线程得到错误的输出。使用多线程进行测试表明您之前的实现不正确。
希望这对您有所帮助。
编辑:我得到的输出是 the same as yours对于 5x5 矩阵。
{kind=link}
关于c++ - openMP C++ 简单并行区域 - 输出不一致,我们在Stack Overflow上找到一个类似的问题: https://stackoverflow.com/questions/37636245/