我一直在尝试从 DM 网站抓取用户评论,但没有成功。 示例页面:https://www.dm.de/l-oreal-men-expert-men-expert-vita-lift-vitalisierende-feuchtigkeitspflege-p3600523606276.html
我尝试使用 beautifulsoup4 和 scrapy 加载产品详情页面。
from bs4 import BeautifulSoup
import requests
url = "https://www.dm.de/l-oreal-men-expert-men-expert-vita-lift-vitalisierende-feuchtigkeitspflege-p3600523606276.html"
response = requests.get(url)
print(response.text)
运行代码不会显示任何评论内容 - 就像您从 amazon.de 获得的一样!它只显示来自网站的脚本。
编辑: 从Dev工具中可以看出,reviwes以JSON的形式存放在以下文件夹中。这正是我要提取的内容。
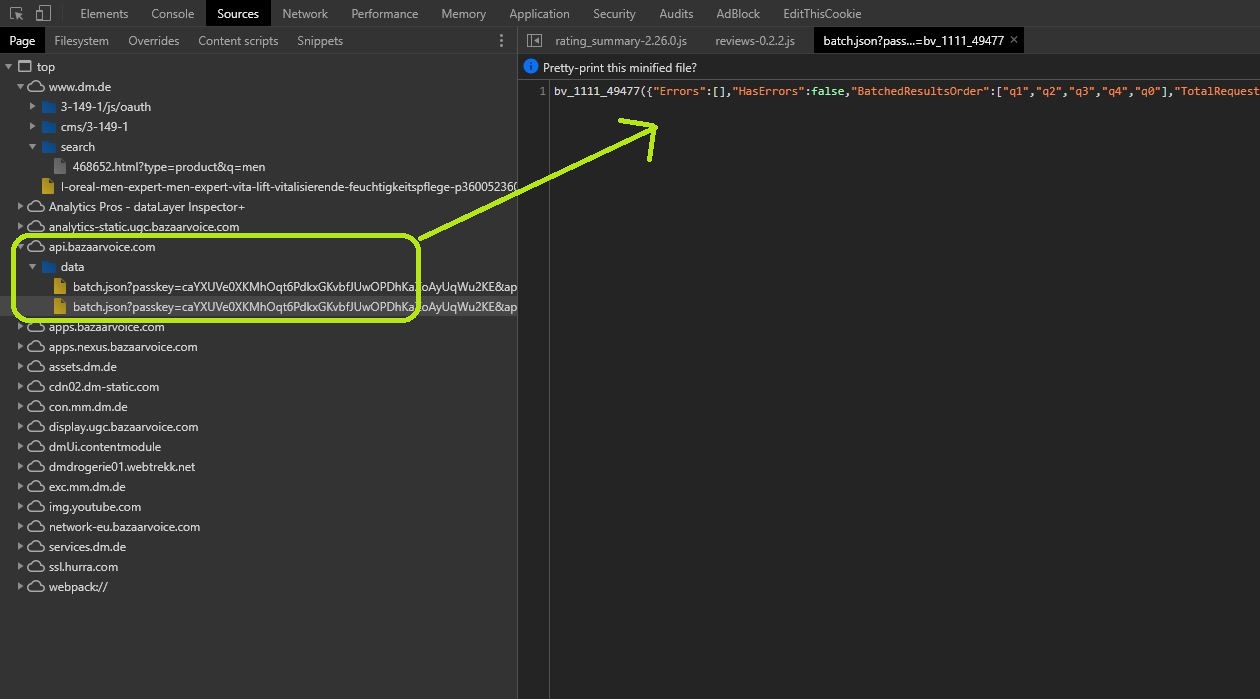{kind=link}
最佳答案
与大多数现代网站一样,dm.de 似乎只在页面初始加载后通过 javascript 加载内容。这是有问题的,因为 pythons 请求库和 scrapy 只处理 http,但不加载任何 javascript。
同样的事情也发生在亚马逊上,但它被检测到并且你得到了一个无 javascript 的版本。
您可以通过在浏览器中禁用 javascript 然后打开您想要抓取的网站来亲自尝试。
解决方案包括使用支持javascript的抓取器,或者使用自动浏览器抓取(使用完整的浏览器当然也支持js)。 Selenium 和 Chrome 对我很有效。
关于python - 从 DM.de 抓取客户评论,我们在Stack Overflow上找到一个类似的问题: https://stackoverflow.com/questions/57220006/