我有一个数据框 hash_file,它有两列 VARIABLE 和 concept_id。
hash_file = pd.DataFrame({'VARIABLE':['Tes ','Exam ','Evaluation '],'concept_id': [1,2,3]})
要去除这两列值中的空格,我使用以下代码
hash_file['VARIABLE']=hash_file['VARIABLE'].astype(str).str.strip()
hash_file['concept_id']=hash_file['concept_id'].astype(str).str.strip()
虽然这很好用,但我不能使用这种方法,因为我的真实数据框有超过 150 列。
有没有办法一次从所有列及其值中去除空格?就像在一条线上?
更新截图
最佳答案
按 DataFrame.select_dtypes 仅选择字符串列并使用 Series.str.strip每列 DataFrame.apply :
cols = hash_file.select_dtypes(object).columns
hash_file[cols] = hash_file[cols].apply(lambda x: x.str.strip())
如果字符串中没有缺失值:
cols = hash_file.select_dtypes(object).columns
hash_file[cols] = hash_file[cols].applymap(lambda x: x.strip())
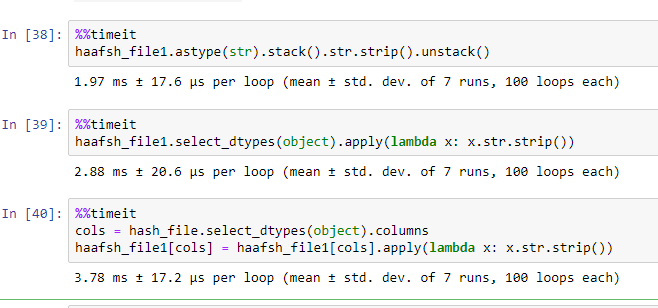
性能:
[9000 rows x 150 columns] (50% strings columns)
hash_file = pd.DataFrame({'VARIABLE':['Tes ','Exam ','Evaluation '],'concept_id': [1,2,3]})
hash_file = pd.concat([hash_file] * 3000, ignore_index=True)
hash_file = pd.concat([hash_file] * 75, ignore_index=True, axis=1)
In [14]: %%timeit
...: cols = hash_file.select_dtypes(object).columns
...: hash_file[cols] = hash_file[cols].applymap(lambda x: x.strip())
...:
338 ms ± 14 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
In [15]: %%timeit
...: cols = hash_file.select_dtypes(object).columns
...: hash_file[cols] = hash_file[cols].apply(lambda x: x.str.strip())
...:
368 ms ± 7.77 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
In [16]: %%timeit
...: cols = hash_file.select_dtypes(object).columns
...: hash_file[cols] = hash_file[cols].stack().str.strip().unstack()
...:
818 ms ± 17.5 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
In [17]: %%timeit
...: hash_file.astype(str).applymap(lambda x: x.strip())
...:
1.09 s ± 21.3 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
In [18]: %%timeit
...: hash_file.astype(str).apply(lambda x: x.str.strip())
...:
1.2 s ± 32.7 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
In [19]: %%timeit
...: hash_file.astype(str).stack().str.strip().unstack()
...:
2 s ± 25.3 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
关于python - 比单个列一次跨数据框剥离空间的优雅方式,我们在Stack Overflow上找到一个类似的问题: https://stackoverflow.com/questions/57369207/