我正在尝试将 SPSS 语法文件转换为可读的 HTML。除了在 HTML 文件中插入一个(单个)不可打印字符之外,它的工作几乎完美。它似乎没有 ASCII 代码,看起来像一个小点。这会带来麻烦。
它(仅)出现在 HTML 文件的第二行,始终对应于原始文件的第一行。这可能暗示了 Python 的哪一行导致了问题(请参阅注释)
似乎导致此问题的代码是
rfil = open(fil,"r") #rfil = Read File, original syntax
wfil = open(txtFil,"w") #wfil = Write File, HTML output
#Line below causes problem??
wfil.write("<ol class='code'>\n<li>")
cnt = 0
for line in rfil:
if cnt == 0:
#Line below causes problem??
wfil.write(line.rstrip("\n").replace("'",''').replace('"','"'))
elif len(line) > 1:
wfil.write("</li>\n<li>" + line.strip("\n").replace("'",''').replace('"','"'))
else:
wfil.write("<br /><br />")
cnt += 1
wfil.write("</li>\n</ol>")
wfil.close()
rfil.close()
结果的屏幕截图
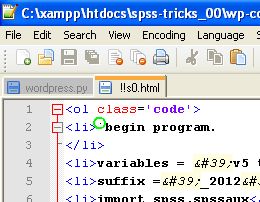
最佳答案
输入文件似乎以 byte order mark (BOM) 开头,表示UTF-8编码。您可以通过使用
打开文件将其解码为 Unicode 字符串import codecs
rfil = codecs.open(fil, "r", "utf_8_sig")
utf_8_sig 编码在开始时会跳过 BOM。
有些程序可以识别 BOM,有些则不能。要写出不带 BOM 的文件,请使用
wfil = codecs.open(txtFil, "w", "utf_8")
关于python - 避免Python编写的html文件中的不可打印字符,我们在Stack Overflow上找到一个类似的问题: https://stackoverflow.com/questions/16538883/